Related Research Articles
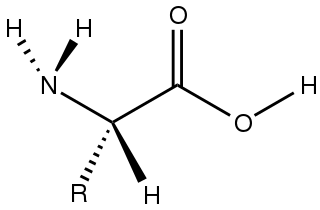
Amino acids are organic compounds that contain amino (–NH2) and carboxyl (–COOH) functional groups, along with a side chain (R group) specific to each amino acid. The key elements of an amino acid are carbon (C), hydrogen (H), oxygen (O), and nitrogen (N), although other elements are found in the side chains of certain amino acids. About 500 naturally occurring amino acids are known as of 1983 (though only 20 appear in the genetic code) and can be classified in many ways. They can be classified according to the core structural functional groups' locations as alpha- (α-), beta- (β-), gamma- (γ-) or delta- (δ-) amino acids; other categories relate to polarity, pH level, and side chain group type (aliphatic, acyclic, aromatic, containing hydroxyl or sulfur, etc.). In the form of proteins, amino acid residues form the second-largest component (water is the largest) of human muscles and other tissues. Beyond their role as residues in proteins, amino acids participate in a number of processes such as neurotransmitter transport and biosynthesis.

Proteins are large biomolecules and macromolecules that comprise one or more long chains of amino acid residues. Proteins perform a vast array of functions within organisms, including catalysing metabolic reactions, DNA replication, responding to stimuli, providing structure to cells and organisms, and transporting molecules from one location to another. Proteins differ from one another primarily in their sequence of amino acids, which is dictated by the nucleotide sequence of their genes, and which usually results in protein folding into a specific 3D structure that determines its activity.

Cysteine (symbol Cys or C; ) is a semiessential proteinogenic amino acid with the formula HOOC-CH-(NH2)-CH2-SH. The thiol side chain in cysteine often participates in enzymatic reactions as a nucleophile. The thiol is susceptible to oxidation to give the disulfide derivative cystine, which serves an important structural role in many proteins. When used as a food additive, it has the E number E920. It is encoded by the codons UGU and UGC.
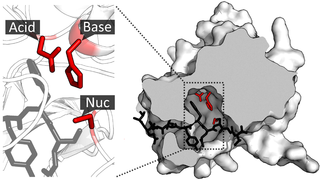
A catalytic triad is a set of three coordinated amino acids that can be found in the active site of some enzymes. Catalytic triads are most commonly found in hydrolase and transferase enzymes. An Acid-Base-Nucleophile triad is a common motif for generating a nucleophilic residue for covalent catalysis. The residues form a charge-relay network to polarise and activate the nucleophile, which attacks the substrate, forming a covalent intermediate which is then hydrolysed to release the product and regenerate free enzyme. The nucleophile is most commonly a serine or cysteine amino acid, but occasionally threonine or even selenocysteine. The 3D structure of the enzyme brings together the triad residues in a precise orientation, even though they may be far apart in the sequence.

FGF1, also known as acidic fibroblast growth factor (aFGF), is a growth factor and signaling protein encoded by the FGF1 gene. It is synthesized as a 155 amino acid polypeptide, whose mature form is a non-glycosylated 17-18 kDa protein. Fibroblast growth factor protein was first purified in 1975, but soon afterwards others using different conditions isolated acidic FGF, Heparin-binding growth factor-1, and Endothelial cell growth factor-1. Gene sequencing revealed that this group was actually the same growth factor and that FGF1 was a member of a family of FGF proteins.

EF-Tu is a prokaryotic elongation factor responsible for catalyzing the binding of an aminoacyl-tRNA (aa-tRNA) to the ribosome. It is a G-protein, and facilitates the selection and binding of an aa-tRNA to the A-site of the ribosome. As a reflection of its crucial role in translation, EF-Tu is one of the most abundant and highly conserved proteins in prokaryotes. It is found in eukaryotic mitochrondria as TUFM.

A serine/threonine protein kinase is a kinase enzyme that phosphorylates the OH group of serine or threonine. At least 125 of the 500+ human protein kinases are serine/threonine kinases (STK).

Hydrophobins are a group of small cysteine-rich proteins that are expressed only by filamentous fungi that are lichenized or not. They are known for their ability to form a hydrophobic (water-repellent) coating on the surface of an object. They were first discovered and separated in Schizophyllum commune in 1991. Based on differences in hydropathy patterns and biophysical properties, they can be divided into two categories: class I and class II. Hydrophobins can self-assemble into a monolayer on hydrophilic:hydrophobic interfaces such as a water:air interface. Class I monolayer contains the same core structure as amyloid fibrils, and is positive to Congo red and thioflavin T. The monolayer formed by class I hydrophobins has a highly ordered structure, and can only be dissociated by concentrated trifluoroacetate or formic acid. Monolayer assembly involves large structural rearrangements with respect to the monomer.
In enzymology, nitrile hydratases are mononuclear iron or non-corrinoid cobalt enzymes that catalyse the hydration of diverse nitriles to their corresponding amides
Protein L was first isolated from the surface of bacterial species Peptostreptococcus magnus and was found to bind immunoglobulins through L chain interaction, from which the name was suggested. It consists of 719 amino acid residues. The molecular weight of Protein L purified from the cell walls of Peptostreptoccus magnus was first estimated as 95kD by SDS-PAGE in the presence of reducing agent 2-mercaptoethanol, while the molecular weight was determined to 76kD by gel chromotography in the presence of 6 M guanidine HCl. Protein L does not contain any interchain disulfide loops, nor does it consist of disulfide-linked subunits. It is an acidic molecule with a pI of 4.0. Unlike Protein A and Protein G, which bind to the Fc region of immunoglobulins (antibodies), Protein L binds antibodies through light chain interactions. Since no part of the heavy chain is involved in the binding interaction, Protein L binds a wider range of antibody classes than Protein A or G. Protein L binds to representatives of all antibody classes, including IgG, IgM, IgA, IgE and IgD. Single chain variable fragments (scFv) and Fab fragments also bind to Protein L.
Branched-chain amino acid aminotransferase (BCAT), also known as branched-chain amino acid transaminase, is an aminotransferase enzyme (EC 2.6.1.42) which acts upon branched-chain amino acids (BCAAs). It is encoded by the BCAT2 gene in humans. The BCAT enzyme catalyzes the conversion of BCAAs and α-ketoglutarate into branched chain α-keto acids and glutamate.

POU domain, class 2, transcription factor 1 is a protein that in humans is encoded by the POU2F1 gene.

Cathepsin D is a protein that in humans is encoded by the CTSD gene. This gene encodes a lysosomal aspartyl protease composed of a protein dimer of disulfide-linked heavy and light chains, both produced from a single protein precursor. Cathepsin D is an aspartic endo-protease that is ubiquitously distributed in lysosomes. The main function of cathepsin D is to degrade proteins and activate precursors of bioactive proteins in pre-lysosomal compartments. This proteinase, which is a member of the peptidase A1 family, has a specificity similar to but narrower than that of pepsin A. Transcription of the CTSD gene is initiated from several sites, including one that is a start site for an estrogen-regulated transcript. Mutations in this gene are involved in the pathogenesis of several diseases, including breast cancer and possibly Alzheimer disease. Homozygous deletion of the CTSD gene leads to early lethality in the postnatal phase. Deficiency of CTSD gene has been reported an underlying cause of neuronal ceroid lipofuscinosis (NCL).
Insulin-like growth factor-binding protein 7 is a protein that in humans is encoded by the IGFBP7 gene. The major function of the protein is the regulation of availability of insulin-like growth factors (IGFs) in tissue as well as in modulating IGF binding to its receptors. IGFBP7 binds to IGF with high affinity. It also stimulates cell adhesion. The protein is implicated in some cancers.

Sialic acid-binding Ig-like lectin 7 is a protein that in humans is encoded by the SIGLEC7 gene. SIGLEC7 has also been designated as CD328.

Triadin, also known as TRDN, is a human gene associated with the release of calcium ions from the sarcoplasmic reticulum triggering muscular contraction through calcium-induced calcium release. Triadin is a multiprotein family, arising from different processing of the TRDN gene on chromosome 6. It is a transmembrane protein on the sarcoplasmic reticulum due to a well defined hydrophobic section and it forms a quaternary complex with the cardiac ryanodine receptor (RYR2), calsequestrin (CASQ2) and junctin proteins. The luminal (inner compartment of the sarcoplasmic reticulum) section of Triadin has areas of highly charged amino acid residues that act as luminal Ca2+ receptors. Triadin is also able to sense luminal Ca2+ concentrations by mediating interactions between RYR2 and CASQ2. Triadin has several different forms; Trisk 95 and Trisk 51, which are expressed in skeletal muscle, and Trisk 32 (CT1), which is mainly expressed in cardiac muscle.
Scorpion toxins are proteins found in the venom of scorpions. Their toxic effect may be mammal- or insect-specific and acts by binding with varying degrees of specificity to members of the Voltage-gated ion channel superfamily; specifically, voltage-gated sodium channels, voltage-gated potassium channels, and Transient Receptor Potential (TRP) channels. The result of this action is to activate or inhibit the action of these channels in the nervous and cardiac organ systems. For instance, α-scorpion toxins MeuNaTxα-12 and MeuNaTxα-13 from Mesobuthus eupeus are neurotoxins that target voltage-gated Na+ channels (Navs), inhibiting fast inactivation. In vivo assays of MeuNaTxα-12 and MeuNaTxα-13 effects on mammalian and insect Navs show differential potency. These recombinants exhibit their preferential affinity for mammalian and insect Na+ channels at the α-like toxins' active site, site 3, in order to inactivate the cell membrane depolarization faster[6]. The varying sensitivity of different Navs to MeuNaTxα-12 and MeuNaTxα-13 may be dependent on the substitution of a conserved Valine residue for a Phenylalanine residue at position 1630 of the LD4:S3-S4 subunit or due to various changes in residues in the LD4:S5-S6 subunit of the Navs. Ultimately, these actions can serve the purpose of warding off predators by causing pain or to subdue predators.
Actin-associated LIM protein (ALP), also known as PDZ and LIM domain protein 3 is a protein that in humans is encoded by the PDLIM3 gene. ALP is highly expressed in cardiac and skeletal muscle, where it localizes to Z-discs and intercalated discs. ALP functions to enhance the crosslinking of actin by alpha actinin-2 and also appears to be essential for right ventricular chamber formation and contractile function.

Ceratocystis platani is a fungus that causes a disease on plane trees in the genus Platanus.
D-Amino acids are amino acids where the stereogenic carbon alpha to the amino group has the D-configuration. For most naturally-occurring amino acids, this carbon has the L-configuration. D-Amino acids are occasionally found in nature as residues in proteins. They are formed from ribosomally-derived D-amino acid residues.
References
- ↑ Chen, Hongxin; Kovalchuk, Andriy; Keriö, Susanna; Asiegbu, Fred O. (20 January 2017). "Distribution and bioinformatic analysis of the cerato-platanin protein family in Dikarya". Mycologia. 105 (2013): 1479–1488. doi:10.3852/13-115. PMID 23928425. S2CID 23984426.
- ↑ Sbrana F, Bongini L, Cappugi G, Fanelli D, Guarino A, Pazzagli L, Scala A, Vassalli M, Zoppi C, Tiribilli B (September 2007). "Atomic force microscopy images suggest aggregation mechanism in cerato-platanin" (PDF). Eur. Biophys. J. 36 (7): 727–32. doi:10.1007/s00249-007-0159-x. PMID 17431609. S2CID 11585837.
- ↑ Dabrowski-Tumanski, Pawel; Sulkowska, Joanna I. (2017-03-28). "Topological knots and links in proteins". Proceedings of the National Academy of Sciences. 114 (13): 3415–3420. doi: 10.1073/pnas.1615862114 . ISSN 0027-8424. PMC 5380043 . PMID 28280100.
- ↑ Pazzagli L, Cappugi G, Manao G, Camici G, Santini A, Scala A (August 1999). "Purification, characterization, and amino acid sequence of cerato-platanin, a new phytotoxic protein from Ceratocystis fimbriata f. sp. platani". J. Biol. Chem. 274 (35): 24959–64. doi: 10.1074/jbc.274.35.24959 . PMID 10455173.
- ↑ Carresi L, Pantera B, Zoppi C, Cappugi G, Oliveira AL, Pertinhez TA, Spisni A, Scala A, Pazzagli L (October 2006). "Cerato-platanin, a phytotoxic protein from Ceratocystis fimbriata: expression in Pichia pastoris, purification and characterization". Protein Expr. Purif. 49 (2): 159–67. doi:10.1016/j.pep.2006.07.006. PMID 16931046.