Related Research Articles
In computer science, a B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree, allowing for nodes with more than two children. Unlike other self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as databases and file systems.
In computer science, a red–black tree is a self-balancing binary search tree data structure noted for fast storage and retrieval of ordered information. The nodes in a red-black tree hold an extra "color" bit, often drawn as red and black, which help ensure that the tree is always approximately balanced.
Categorization is a type of cognition involving conceptual differentiation between characteristics of conscious experience, such as objects, events, or ideas. It involves the abstraction and differentiation of aspects of experience by sorting and distinguishing between groupings, through classification or typification on the basis of traits, features, similarities or other criteria that are universal to the group. Categorization is considered one of the most fundamental cognitive abilities, and it is studied particularly by psychology and cognitive linguistics.

A decision tree is a decision support hierarchical model that uses a tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm that only contains conditional control statements.

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.
Decision tree learning is a supervised learning approach used in statistics, data mining and machine learning. In this formalism, a classification or regression decision tree is used as a predictive model to draw conclusions about a set of observations.

R-trees are tree data structures used for spatial access methods, i.e., for indexing multi-dimensional information such as geographical coordinates, rectangles or polygons. The R-tree was proposed by Antonin Guttman in 1984 and has found significant use in both theoretical and applied contexts. A common real-world usage for an R-tree might be to store spatial objects such as restaurant locations or the polygons that typical maps are made of: streets, buildings, outlines of lakes, coastlines, etc. and then find answers quickly to queries such as "Find all museums within 2 km of my current location", "retrieve all road segments within 2 km of my location" or "find the nearest gas station". The R-tree can also accelerate nearest neighbor search for various distance metrics, including great-circle distance.
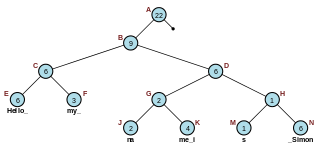
In computer programming, a rope, or cord, is a data structure composed of smaller strings that is used to efficiently store and manipulate a very long string. For example, a text editing program may use a rope to represent the text being edited, so that operations such as insertion, deletion, and random access can be done efficiently.
A B+ tree is an m-ary tree with a variable but often large number of children per node. A B+ tree consists of a root, internal nodes and leaves. The root may be either a leaf or a node with two or more children.
In data processing R*-trees are a variant of R-trees used for indexing spatial information. R*-trees have slightly higher construction cost than standard R-trees, as the data may need to be reinserted; but the resulting tree will usually have a better query performance. Like the standard R-tree, it can store both point and spatial data. It was proposed by Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger in 1990.
An AA tree in computer science is a form of balanced tree used for storing and retrieving ordered data efficiently. AA trees are named after their originator, Swedish computer scientist Arne Andersson.
In computer science, a ternary search tree is a type of trie where nodes are arranged in a manner similar to a binary search tree, but with up to three children rather than the binary tree's limit of two. Like other prefix trees, a ternary search tree can be used as an associative map structure with the ability for incremental string search. However, ternary search trees are more space efficient compared to standard prefix trees, at the cost of speed. Common applications for ternary search trees include spell-checking and auto-completion.
A skew heap is a heap data structure implemented as a binary tree. Skew heaps are advantageous because of their ability to merge more quickly than binary heaps. In contrast with binary heaps, there are no structural constraints, so there is no guarantee that the height of the tree is logarithmic. Only two conditions must be satisfied:
Conceptual clustering is a machine learning paradigm for unsupervised classification that has been defined by Ryszard S. Michalski in 1980 and developed mainly during the 1980s. It is distinguished from ordinary data clustering by generating a concept description for each generated class. Most conceptual clustering methods are capable of generating hierarchical category structures; see Categorization for more information on hierarchy. Conceptual clustering is closely related to formal concept analysis, decision tree learning, and mixture model learning.
Category utility is a measure of "category goodness" defined in Gluck & Corter (1985) and Corter & Gluck (1992). It attempts to maximize both the probability that two objects in the same category have attribute values in common, and the probability that objects from different categories have different attribute values. It was intended to supersede more limited measures of category goodness such as "cue validity" and "collocation index". It provides a normative information-theoretic measure of the predictive advantage gained by the observer who possesses knowledge of the given category structure over the observer who does not possess knowledge of the category structure. In this sense the motivation for the category utility measure is similar to the information gain metric used in decision tree learning. In certain presentations, it is also formally equivalent to the mutual information, as discussed below. A review of category utility in its probabilistic incarnation, with applications to machine learning, is provided in Witten & Frank.
Hilbert R-tree, an R-tree variant, is an index for multidimensional objects such as lines, regions, 3-D objects, or high-dimensional feature-based parametric objects. It can be thought of as an extension to B+-tree for multidimensional objects.
An incremental decision tree algorithm is an online machine learning algorithm that outputs a decision tree. Many decision tree methods, such as C4.5, construct a tree using a complete dataset. Incremental decision tree methods allow an existing tree to be updated using only new individual data instances, without having to re-process past instances. This may be useful in situations where the entire dataset is not available when the tree is updated, the original data set is too large to process or the characteristics of the data change over time.
In computer science, data stream clustering is defined as the clustering of data that arrive continuously such as telephone records, multimedia data, financial transactions etc. Data stream clustering is usually studied as a streaming algorithm and the objective is, given a sequence of points, to construct a good clustering of the stream, using a small amount of memory and time.
In computer science, M-trees are tree data structures that are similar to R-trees and B-trees. It is constructed using a metric and relies on the triangle inequality for efficient range and k-nearest neighbor (k-NN) queries. While M-trees can perform well in many conditions, the tree can also have large overlap and there is no clear strategy on how to best avoid overlap. In addition, it can only be used for distance functions that satisfy the triangle inequality, while many advanced dissimilarity functions used in information retrieval do not satisfy this.
In network theory, collective classification is the simultaneous prediction of the labels for multiple objects, where each label is predicted using information about the object's observed features, the observed features and labels of its neighbors, and the unobserved labels of its neighbors. Collective classification problems are defined in terms of networks of random variables, where the network structure determines the relationship between the random variables. Inference is performed on multiple random variables simultaneously, typically by propagating information between nodes in the network to perform approximate inference. Approaches that use collective classification can make use of relational information when performing inference. Examples of collective classification include predicting attributes of individuals in a social network, classifying webpages in the World Wide Web, and inferring the research area of a paper in a scientific publication dataset.
References
- ↑ Fisher, Douglas (1987). "Knowledge acquisition via incremental conceptual clustering". Machine Learning. 2 (2): 139–172. doi: 10.1007/BF00114265 .
- ↑ Fisher, Douglas H. (July 1987). "Improving inference through conceptual clustering". Proceedings of the 1987 AAAI Conferences. AAAI Conference. Seattle Washington. pp. 461–465.
- ↑ Wayne Iba and Pat Langley. "Cobweb models of categorization and probabilistic concept formation". In Emmanuel M. Pothos and Andy J. Wills (ed.). Formal approaches in categorization. Cambridge: Cambridge University Press. pp. 253–273. ISBN 9780521190480.