Kinematics is a subfield of physics and mathematics, developed in classical mechanics, that describes the motion of points, bodies (objects), and systems of bodies without considering the forces that cause them to move. Kinematics, as a field of study, is often referred to as the "geometry of motion" and is occasionally seen as a branch of both applied and pure mathematics since it can be studied without considering the mass of a body or the forces acting upon it. A kinematics problem begins by describing the geometry of the system and declaring the initial conditions of any known values of position, velocity and/or acceleration of points within the system. Then, using arguments from geometry, the position, velocity and acceleration of any unknown parts of the system can be determined. The study of how forces act on bodies falls within kinetics, not kinematics. For further details, see analytical dynamics.
In mathematics, the dot product or scalar product is an algebraic operation that takes two equal-length sequences of numbers, and returns a single number. In Euclidean geometry, the dot product of the Cartesian coordinates of two vectors is widely used. It is often called the inner product of Euclidean space, even though it is not the only inner product that can be defined on Euclidean space.
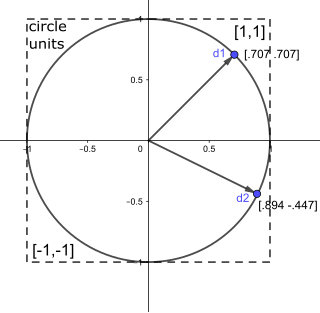
In mathematics, a unit vector in a normed vector space is a vector of length 1. A unit vector is often denoted by a lowercase letter with a circumflex, or "hat", as in .
In mechanics and geometry, the 3D rotation group, often denoted SO(3), is the group of all rotations about the origin of three-dimensional Euclidean space under the operation of composition.
In mathematics, the Laplace operator or Laplacian is a differential operator given by the divergence of the gradient of a scalar function on Euclidean space. It is usually denoted by the symbols , (where is the nabla operator), or . In a Cartesian coordinate system, the Laplacian is given by the sum of second partial derivatives of the function with respect to each independent variable. In other coordinate systems, such as cylindrical and spherical coordinates, the Laplacian also has a useful form. Informally, the Laplacian Δf (p) of a function f at a point p measures by how much the average value of f over small spheres or balls centered at p deviates from f (p).
Unit quaternions, known as versors, provide a convenient mathematical notation for representing spatial orientations and rotations of elements in three dimensional space. Specifically, they encode information about an axis-angle rotation about an arbitrary axis. Rotation and orientation quaternions have applications in computer graphics, computer vision, robotics, navigation, molecular dynamics, flight dynamics, orbital mechanics of satellites, and crystallographic texture analysis.
In the mathematical field of differential geometry, a metric tensor is an additional structure on a manifold M that allows defining distances and angles, just as the inner product on a Euclidean space allows defining distances and angles there. More precisely, a metric tensor at a point p of M is a bilinear form defined on the tangent space at p, and a metric field on M consists of a metric tensor at each point p of M that varies smoothly with p.
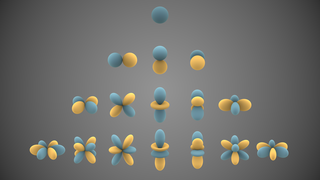
In mathematics and physical science, spherical harmonics are special functions defined on the surface of a sphere. They are often employed in solving partial differential equations in many scientific fields. The table of spherical harmonics contains a list of common spherical harmonics.
In linear algebra, linear transformations can be represented by matrices. If is a linear transformation mapping to and is a column vector with entries, then
In mathematics and physics, the Christoffel symbols are an array of numbers describing a metric connection. The metric connection is a specialization of the affine connection to surfaces or other manifolds endowed with a metric, allowing distances to be measured on that surface. In differential geometry, an affine connection can be defined without reference to a metric, and many additional concepts follow: parallel transport, covariant derivatives, geodesics, etc. also do not require the concept of a metric. However, when a metric is available, these concepts can be directly tied to the "shape" of the manifold itself; that shape is determined by how the tangent space is attached to the cotangent space by the metric tensor. Abstractly, one would say that the manifold has an associated (orthonormal) frame bundle, with each "frame" being a possible choice of a coordinate frame. An invariant metric implies that the structure group of the frame bundle is the orthogonal group O(p, q). As a result, such a manifold is necessarily a (pseudo-)Riemannian manifold. The Christoffel symbols provide a concrete representation of the connection of (pseudo-)Riemannian geometry in terms of coordinates on the manifold. Additional concepts, such as parallel transport, geodesics, etc. can then be expressed in terms of Christoffel symbols.

The vector projection of a vector a on a nonzero vector b is the orthogonal projection of a onto a straight line parallel to b. The projection of a onto b is often written as or a∥b.
A parametric surface is a surface in the Euclidean space which is defined by a parametric equation with two parameters :\mathbb {R} ^{2}\to \mathbb {R} ^{3}} . Parametric representation is a very general way to specify a surface, as well as implicit representation. Surfaces that occur in two of the main theorems of vector calculus, Stokes' theorem and the divergence theorem, are frequently given in a parametric form. The curvature and arc length of curves on the surface, surface area, differential geometric invariants such as the first and second fundamental forms, Gaussian, mean, and principal curvatures can all be computed from a given parametrization.
Angular distance or angular separation is the measure of the angle between the orientation of two straight lines, rays, or vectors in three-dimensional space, or the central angle subtended by the radii through two points on a sphere. When the rays are lines of sight from an observer to two points in space, it is known as the apparent distance or apparent separation.
In geometry, various formalisms exist to express a rotation in three dimensions as a mathematical transformation. In physics, this concept is applied to classical mechanics where rotational kinematics is the science of quantitative description of a purely rotational motion. The orientation of an object at a given instant is described with the same tools, as it is defined as an imaginary rotation from a reference placement in space, rather than an actually observed rotation from a previous placement in space.

In mathematics, the axis–angle representation parameterizes a rotation in a three-dimensional Euclidean space by two quantities: a unit vector e indicating the direction (geometry) of an axis of rotation, and an angle of rotation θ describing the magnitude and sense of the rotation about the axis. Only two numbers, not three, are needed to define the direction of a unit vector e rooted at the origin because the magnitude of e is constrained. For example, the elevation and azimuth angles of e suffice to locate it in any particular Cartesian coordinate frame.
In mathematics and statistics, a circular mean or angular mean is a mean designed for angles and similar cyclic quantities, such as times of day, and fractional parts of real numbers.

In celestial mechanics, a Kepler orbit is the motion of one body relative to another, as an ellipse, parabola, or hyperbola, which forms a two-dimensional orbital plane in three-dimensional space. A Kepler orbit can also form a straight line. It considers only the point-like gravitational attraction of two bodies, neglecting perturbations due to gravitational interactions with other objects, atmospheric drag, solar radiation pressure, a non-spherical central body, and so on. It is thus said to be a solution of a special case of the two-body problem, known as the Kepler problem. As a theory in classical mechanics, it also does not take into account the effects of general relativity. Keplerian orbits can be parametrized into six orbital elements in various ways.
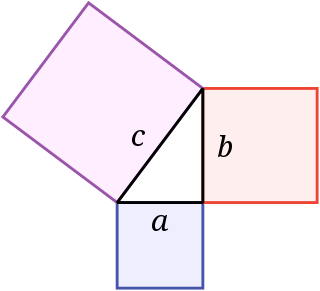
In mathematics, the Pythagorean theorem or Pythagoras' theorem is a fundamental relation in Euclidean geometry between the three sides of a right triangle. It states that the area of the square whose side is the hypotenuse is equal to the sum of the areas of the squares on the other two sides.
The following are important identities in vector algebra. Identities that involve the magnitude of a vector , or the dot product of two vectors A·B, apply to vectors in any dimension. Identities that use the cross product A×B are defined only in three dimensions. Most of these relations can be dated to founder of vector calculus Josiah Willard Gibbs, if not earlier.
In orbital mechanics, Gauss's method is used for preliminary orbit determination from at least three observations of the orbiting body of interest at three different times. The required information are the times of observations, the position vectors of the observation points, the direction cosine vector of the orbiting body from the observation points and general physical data.






































