
In molecular biology, DNA replication is the biological process of producing two identical replicas of DNA from one original DNA molecule. DNA replication occurs in all living organisms acting as the most essential part for biological inheritance. This is essential for cell division during growth and repair of damaged tissues, while it also ensures that each of the new cells receives its own copy of the DNA. The cell possesses the distinctive property of division, which makes replication of DNA essential.

A primer is a short single-stranded nucleic acid used by all living organisms in the initiation of DNA synthesis. DNA polymerase enzymes are only capable of adding nucleotides to the 3’-end of an existing nucleic acid, requiring a primer be bound to the template before DNA polymerase can begin a complementary strand. DNA polymerase adds nucleotides after binding to the RNA primer and synthesizes the whole strand. Later, the RNA strands must be removed accurately and replace them with DNA nucleotides forming a gap region known as a nick that is filled in using an enzyme called ligase. The removal process of the RNA primer requires several enzymes, such as Fen1, Lig1, and others that work in coordination with DNA polymerase, to ensure the removal of the RNA nucleotides and the addition of DNA nucleotides. Living organisms use solely RNA primers, while laboratory techniques in biochemistry and molecular biology that require in vitro DNA synthesis usually use DNA primers, since they are more temperature stable. Primers can be designed in laboratory for specific reactions such as polymerase chain reaction (PCR). When designing PCR primers, there are specific measures that must be taken into consideration, like the melting temperature of the primers and the annealing temperature of the reaction itself. Moreover, the DNA binding sequence of the primer in vitro has to be specifically chosen, which is done using a method called basic local alignment search tool (BLAST) that scans the DNA and finds specific and unique regions for the primer to bind.

Transcription is the process of copying a segment of DNA into RNA. The segments of DNA transcribed into RNA molecules that can encode proteins are said to produce messenger RNA (mRNA). Other segments of DNA are copied into RNA molecules called non-coding RNAs (ncRNAs). mRNA comprises only 1–3% of total RNA samples. Less than 2% of the human genome can be transcribed into mRNA, while at least 80% of mammalian genomic DNA can be actively transcribed, with the majority of this 80% considered to be ncRNA.

In molecular biology, RNA polymerase, or more specifically DNA-directed/dependent RNA polymerase (DdRP), is an enzyme that synthesizes RNA from a DNA template.

A DNA polymerase is a member of a family of enzymes that catalyze the synthesis of DNA molecules from nucleoside triphosphates, the molecular precursors of DNA. These enzymes are essential for DNA replication and usually work in groups to create two identical DNA duplexes from a single original DNA duplex. During this process, DNA polymerase "reads" the existing DNA strands to create two new strands that match the existing ones. These enzymes catalyze the chemical reaction
DNA primase is an enzyme involved in the replication of DNA and is a type of RNA polymerase. Primase catalyzes the synthesis of a short RNA segment called a primer complementary to a ssDNA template. After this elongation, the RNA piece is removed by a 5' to 3' exonuclease and refilled with DNA.

DNA polymerase I is an enzyme that participates in the process of prokaryotic DNA replication. Discovered by Arthur Kornberg in 1956, it was the first known DNA polymerase. It was initially characterized in E. coli and is ubiquitous in prokaryotes. In E. coli and many other bacteria, the gene that encodes Pol I is known as polA. The E. coli Pol I enzyme is composed of 928 amino acids, and is an example of a processive enzyme — it can sequentially catalyze multiple polymerisation steps without releasing the single-stranded template. The physiological function of Pol I is mainly to support repair of damaged DNA, but it also contributes to connecting Okazaki fragments by deleting RNA primers and replacing the ribonucleotides with DNA.

DNA polymerase III holoenzyme is the primary enzyme complex involved in prokaryotic DNA replication. It was discovered by Thomas Kornberg and Malcolm Gefter in 1970. The complex has high processivity and, specifically referring to the replication of the E.coli genome, works in conjunction with four other DNA polymerases. Being the primary holoenzyme involved in replication activity, the DNA Pol III holoenzyme also has proofreading capabilities that corrects replication mistakes by means of exonuclease activity reading 3'→5' and synthesizing 5'→3'. DNA Pol III is a component of the replisome, which is located at the replication fork.

Okazaki fragments are short sequences of DNA nucleotides which are synthesized discontinuously and later linked together by the enzyme DNA ligase to create the lagging strand during DNA replication. They were discovered in the 1960s by the Japanese molecular biologists Reiji and Tsuneko Okazaki, along with the help of some of their colleagues.
The replisome is a complex molecular machine that carries out replication of DNA. The replisome first unwinds double stranded DNA into two single strands. For each of the resulting single strands, a new complementary sequence of DNA is synthesized. The Total result is formation of two new double stranded DNA sequences that are exact copies of the original double stranded DNA sequence.

RNA-dependent RNA polymerase (RdRp) or RNA replicase is an enzyme that catalyzes the replication of RNA from an RNA template. Specifically, it catalyzes synthesis of the RNA strand complementary to a given RNA template. This is in contrast to typical DNA-dependent RNA polymerases, which all organisms use to catalyze the transcription of RNA from a DNA template.
A ribonucleoside tri-phosphate (rNTP) is composed of a ribose sugar, 3 phosphate groups attached via diester bonds to the 5' oxygen on the ribose and a nitrogenous base attached to the 1' carbon on the ribose. rNTP's are also referred to as NTPs while the deoxyribose version is referred to as dNTPs. The nitrogenous base can either be a purine such as a Adenine or Guanine or a pyrimidine such as a Uracil or Cytosine. rNTPs have significant biological uses, they can serve as building blocks of RNA synthesis, primers in DNA replication, stores of chemical energy, chiefly Adenosine triphosphate (ATP) and more.

Prokaryotic DNA Replication is the process by which a prokaryote duplicates its DNA into another copy that is passed on to daughter cells. Although it is often studied in the model organism E. coli, other bacteria show many similarities. Replication is bi-directional and originates at a single origin of replication (OriC). It consists of three steps: Initiation, elongation, and termination.

Eukaryotic DNA replication is a conserved mechanism that restricts DNA replication to once per cell cycle. Eukaryotic DNA replication of chromosomal DNA is central for the duplication of a cell and is necessary for the maintenance of the eukaryotic genome.

T7 DNA polymerase is an enzyme used during the DNA replication of the T7 bacteriophage. During this process, the DNA polymerase “reads” existing DNA strands and creates two new strands that match the existing ones. The T7 DNA polymerase requires a host factor, E. coli thioredoxin, in order to carry out its function. This helps stabilize the binding of the necessary protein to the primer-template to improve processivity by more than 100-fold, which is a feature unique to this enzyme. It is a member of the Family A DNA polymerases, which include E. coli DNA polymerase I and Taq DNA polymerase.
EF-Ts is one of the prokaryotic elongation factors. It is found in human mitochrondria as TSFM. It is similar to eukaryotic EF-1B.

A circular chromosome is a chromosome in bacteria, archaea, mitochondria, and chloroplasts, in the form of a molecule of circular DNA, unlike the linear chromosome of most eukaryotes.
Φ29 DNA polymerase is an enzyme from the bacteriophage Φ29. It is being increasingly used in molecular biology for multiple displacement DNA amplification procedures, and has a number of features that make it particularly suitable for this application. It was discovered and characterised by Spanish scientists Luis Blanco and Margarita Salas.

Illumina dye sequencing is a technique used to determine the series of base pairs in DNA, also known as DNA sequencing. The reversible terminated chemistry concept was invented by Bruno Canard and Simon Sarfati at the Pasteur Institute in Paris. It was developed by Shankar Balasubramanian and David Klenerman of Cambridge University, who subsequently founded Solexa, a company later acquired by Illumina. This sequencing method is based on reversible dye-terminators that enable the identification of single nucleotides as they are washed over DNA strands. It can also be used for whole-genome and region sequencing, transcriptome analysis, metagenomics, small RNA discovery, methylation profiling, and genome-wide protein-nucleic acid interaction analysis.
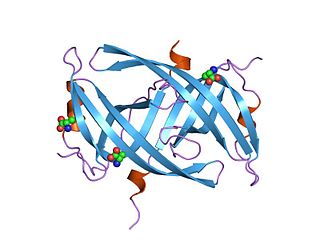
Single-stranded binding proteins (SSBs) are a class of proteins that have been identified in both viruses and organisms from bacteria to humans.






