The Dublin Core, also known as the Dublin Core Metadata Element Set (DCMES), is a set of fifteen main metadata items for describing digital or physical resources. The Dublin Core Metadata Initiative (DCMI) is responsible for formulating the Dublin Core; DCMI is a project of the Association for Information Science and Technology (ASIS&T), a non-profit organization.
The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
A Uniform Resource Identifier (URI) is a unique sequence of characters that identifies a logical or physical resource used by web technologies. URIs may be used to identify anything, including real-world objects, such as people and places, concepts, or information resources such as web pages and books. Some URIs provide a means of locating and retrieving information resources on a network ; these are Uniform Resource Locators (URLs). A URL provides the location of the resource. A URI identifies the resource by name at the specified location or URL. Other URIs provide only a unique name, without a means of locating or retrieving the resource or information about it, these are Uniform Resource Names (URNs). The web technologies that use URIs are not limited to web browsers. URIs are used to identify anything described using the Resource Description Framework (RDF), for example, concepts that are part of an ontology defined using the Web Ontology Language (OWL), and people who are described using the Friend of a Friend vocabulary would each have an individual URI.
The Resource Description Framework (RDF) is a World Wide Web Consortium (W3C) standard originally designed as a data model for metadata. It has come to be used as a general method for description and exchange of graph data. RDF provides a variety of syntax notations and data serialization formats, with Turtle currently being the most widely used notation.
A Uniform Resource Name (URN) is a Uniform Resource Identifier (URI) that uses the urn scheme. URNs are globally unique persistent identifiers assigned within defined namespaces so they will be available for a long period of time, even after the resource which they identify ceases to exist or becomes unavailable. URNs cannot be used to directly locate an item and need not be resolvable, as they are simply templates that another parser may use to find an item.
A digital object identifier (DOI) is a persistent identifier or handle used to uniquely identify various objects, standardized by the International Organization for Standardization (ISO). DOIs are an implementation of the Handle System; they also fit within the URI system. They are widely used to identify academic, professional, and government information, such as journal articles, research reports, data sets, and official publications. DOIs have also been used to identify other types of information resources, such as commercial videos.
A persistent uniform resource locator (PURL) is a uniform resource locator (URL) that is used to redirect to the location of the requested web resource. PURLs redirect HTTP clients using HTTP status codes.
XML namespaces are used for providing uniquely named elements and attributes in an XML document. They are defined in a W3C recommendation. An XML instance may contain element or attribute names from more than one XML vocabulary. If each vocabulary is given a namespace, the ambiguity between identically named elements or attributes can be resolved.
RDFa or Resource Description Framework in Attributes is a W3C Recommendation that adds a set of attribute-level extensions to HTML, XHTML and various XML-based document types for embedding rich metadata within Web documents. The Resource Description Framework (RDF) data-model mapping enables its use for embedding RDF subject-predicate-object expressions within XHTML documents. It also enables the extraction of RDF model triples by compliant user agents.
The Open Biological and Biomedical Ontologies (OBO) Foundry is a group of people dedicated to build and maintain ontologies related to the life sciences. The OBO Foundry establishes a set of principles for ontology development for creating a suite of interoperable reference ontologies in the biomedical domain. Currently, there are more than a hundred ontologies that follow the OBO Foundry principles.
The AgMES initiative was developed by the Food and Agriculture Organization (FAO) of the United Nations and aims to encompass issues of semantic standards in the domain of agriculture with respect to description, resource discovery, interoperability, and data exchange for different types of information resources.
Security Assertion Markup Language 2.0 (SAML 2.0) is a version of the SAML standard for exchanging authentication and authorization identities between security domains. SAML 2.0 is an XML-based protocol that uses security tokens containing assertions to pass information about a principal between a SAML authority, named an Identity Provider, and a SAML consumer, named a Service Provider. SAML 2.0 enables web-based, cross-domain single sign-on (SSO), which helps reduce the administrative overhead of distributing multiple authentication tokens to the user.
A Formal Public Identifier (FPI) is a short piece of specially formatted text that may be used to uniquely identify a product, specification or document. One of their most common uses is as part of document type definitions, but they are also used in the vCard and iCalendar formats to identify the software product that has generated data.
The Handle System is the Corporation for National Research Initiatives's proprietary registry assigning persistent identifiers, or handles, to information resources, and for resolving "those handles into the information necessary to locate, access, and otherwise make use of the resources".
An Extensible Resource Identifier is a scheme and resolution protocol for abstract identifiers compatible with Uniform Resource Identifiers and Internationalized Resource Identifiers, developed by the XRI Technical Committee at OASIS. The goal of XRI was a standard syntax and discovery format for abstract, structured identifiers that are domain-, location-, application-, and transport-independent, so they can be shared across any number of domains, directories, and interaction protocols.
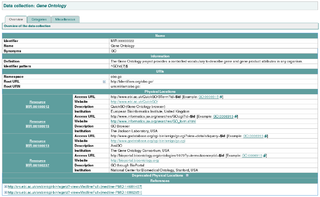
The MIRIAM Registry, a by-product of the MIRIAM Guidelines, is a database of namespaces and associated information that is used in the creation of uniform resource identifiers. It contains the set of community-approved namespaces for databases and resources serving, primarily, the biological sciences domain. These shared namespaces, when combined with 'data collection' identifiers, can be used to create globally unique identifiers for knowledge held in data repositories. For more information on the use of URIs to annotate models, see the specification of SBML Level 2 Version 2.
Semantic Automated Discovery and Integration (SADI) is a lightweight set of fully standards-compliant Semantic Web service design patterns that simplify the publication of services of the type commonly found in bioinformatics and other scientific domains. SADI services utilize Semantic Web technologies at every level of the Web services "stack". Services are described in OWL-DL, where the property restrictions in OWL classes are used to define the properties expected of the input and output data. Invocation of SADI Services is achieved through HTTP POST of RDF data representing OWL Individuals ('instances') of the defined input OWL Class, and the resulting output data will be OWL Individuals of the defined output OWL Class.
The European Legislation Identifier (ELI) ontology is a vocabulary for representing metadata about national and European Union (EU) legislation. It is designed to provide a standardized way to identify and describe the context and content of national or EU legislation, including its purpose, scope, relationships with other legislations and legal basis. This will guarantee easier identification, access, exchange and reuse of legislation for public authorities, professional users, academics and citizens. ELI paves the way for knowledge graphs, based on semantic web standards, of legal gazettes and official journals.
Identifiers.org is a project providing stable and perennial identifiers for data records used in the Life Sciences. The identifiers are provided in the form of Uniform Resource Identifiers (URIs). Identifiers.org is also a resolving system, that relies on collections listed in the MIRIAM Registry to provide direct access to different instances of the identified records.
The Thing Description (TD) (or W3C WoT Thing Description (TD)) is a royalty-free, open information model with a JSON based representation format for the Internet of Things (IoT). A TD provides a unified way to describe the capabilities of an IoT device or service with its offered data model and functions, protocol usage, and further metadata. Using Thing Descriptions help reduce the complexity of integrating IoT devices and their capabilities into IoT applications.