
Image compression is a type of data compression applied to digital images, to reduce their cost for storage or transmission. Algorithms may take advantage of visual perception and the statistical properties of image data to provide superior results compared with generic data compression methods which are used for other digital data.
Digital image processing is the use of a digital computer to process digital images through an algorithm. As a subcategory or field of digital signal processing, digital image processing has many advantages over analog image processing. It allows a much wider range of algorithms to be applied to the input data and can avoid problems such as the build-up of noise and distortion during processing. Since images are defined over two dimensions digital image processing may be modeled in the form of multidimensional systems. The generation and development of digital image processing are mainly affected by three factors: first, the development of computers; second, the development of mathematics ; third, the demand for a wide range of applications in environment, agriculture, military, industry and medical science has increased.

In digital image processing and computer vision, image segmentation is the process of partitioning a digital image into multiple image segments, also known as image regions or image objects. The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze. Image segmentation is typically used to locate objects and boundaries in images. More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.

Sensor fusion is the process of combining sensor data or data derived from disparate sources such that the resulting information has less uncertainty than would be possible when these sources were used individually. For instance, one could potentially obtain a more accurate location estimate of an indoor object by combining multiple data sources such as video cameras and WiFi localization signals. The term uncertainty reduction in this case can mean more accurate, more complete, or more dependable, or refer to the result of an emerging view, such as stereoscopic vision.
In computer science and machine learning, cellular neural networks (CNN) or cellular nonlinear networks (CNN) are a parallel computing paradigm similar to neural networks, with the difference that communication is allowed between neighbouring units only. Typical applications include image processing, analyzing 3D surfaces, solving partial differential equations, reducing non-visual problems to geometric maps, modelling biological vision and other sensory-motor organs.
The image fusion process is defined as gathering all the important information from multiple images, and their inclusion into fewer images, usually a single one. This single image is more informative and accurate than any single source image, and it consists of all the necessary information. The purpose of image fusion is not only to reduce the amount of data but also to construct images that are more appropriate and understandable for the human and machine perception. In computer vision, multisensor image fusion is the process of combining relevant information from two or more images into a single image. The resulting image will be more informative than any of the input images.
Automatic target recognition (ATR) is the ability for an algorithm or device to recognize targets or other objects based on data obtained from sensors.

Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of semantic objects of a certain class in digital images and videos. Well-researched domains of object detection include face detection and pedestrian detection. Object detection has applications in many areas of computer vision, including image retrieval and video surveillance.
Fault detection, isolation, and recovery (FDIR) is a subfield of control engineering which concerns itself with monitoring a system, identifying when a fault has occurred, and pinpointing the type of fault and its location. Two approaches can be distinguished: A direct pattern recognition of sensor readings that indicate a fault and an analysis of the discrepancy between the sensor readings and expected values, derived from some model. In the latter case, it is typical that a fault is said to be detected if the discrepancy or residual goes above a certain threshold. It is then the task of fault isolation to categorize the type of fault and its location in the machinery. Fault detection and isolation (FDI) techniques can be broadly classified into two categories. These include model-based FDI and signal processing based FDI.

Image restoration is the operation of taking a corrupt/noisy image and estimating the clean, original image. Corruption may come in many forms such as motion blur, noise and camera mis-focus. Image restoration is performed by reversing the process that blurred the image and such is performed by imaging a point source and use the point source image, which is called the Point Spread Function (PSF) to restore the image information lost to the blurring process.
Convolutional neural network (CNN) is a regularized type of feed-forward neural network that learns feature engineering by itself via filters optimization. Vanishing gradients and exploding gradients, seen during backpropagation in earlier neural networks, are prevented by using regularized weights over fewer connections. For example, for each neuron in the fully-connected layer, 10,000 weights would be required for processing an image sized 100 × 100 pixels. However, applying cascaded convolution kernels, only 25 neurons are required to process 5x5-sized tiles. Higher-layer features are extracted from wider context windows, compared to lower-layer features.
Data augmentation is a statistical technique which allows maximum likelihood estimation from incomplete data. Data augmentation has important applications in Bayesian analysis, and the technique is widely used in machine learning to reduce overfitting when training machine learning models, achieved by training models on several slightly-modified copies of existing data.

In computer vision, object co-segmentation is a special case of image segmentation, which is defined as jointly segmenting semantically similar objects in multiple images or video frames.

Visual temporal attention is a special case of visual attention that involves directing attention to specific instant of time. Similar to its spatial counterpart visual spatial attention, these attention modules have been widely implemented in video analytics in computer vision to provide enhanced performance and human interpretable explanation of deep learning models.

Neural style transfer (NST) refers to a class of software algorithms that manipulate digital images, or videos, in order to adopt the appearance or visual style of another image. NST algorithms are characterized by their use of deep neural networks for the sake of image transformation. Common uses for NST are the creation of artificial artwork from photographs, for example by transferring the appearance of famous paintings to user-supplied photographs. Several notable mobile apps use NST techniques for this purpose, including DeepArt and Prisma. This method has been used by artists and designers around the globe to develop new artwork based on existent style(s).
LeNet is a convolutional neural network structure proposed by LeCun et al. in 1998. In general, LeNet refers to LeNet-5 and is a simple convolutional neural network. Convolutional neural networks are a kind of feed-forward neural network whose artificial neurons can respond to a part of the surrounding cells in the coverage range and perform well in large-scale image processing.
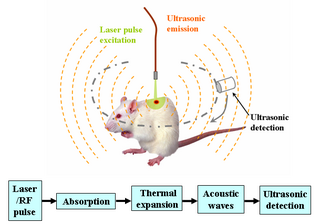
Deep learning in photoacoustic imaging combines the hybrid imaging modality of photoacoustic imaging (PA) with the rapidly evolving field of deep learning. Photoacoustic imaging is based on the photoacoustic effect, in which optical absorption causes a rise in temperature, which causes a subsequent rise in pressure via thermo-elastic expansion. This pressure rise propagates through the tissue and is sensed via ultrasonic transducers. Due to the proportionality between the optical absorption, the rise in temperature, and the rise in pressure, the ultrasound pressure wave signal can be used to quantify the original optical energy deposition within the tissue.

Video super-resolution (VSR) is the process of generating high-resolution video frames from the given low-resolution video frames. Unlike single-image super-resolution (SISR), the main goal is not only to restore more fine details while saving coarse ones, but also to preserve motion consistency.
A vision transformer (ViT) is a transformer designed for computer vision. A ViT breaks down an input image into a series of patches, serialises each patch into a vector, and maps it to a smaller dimension with a single matrix multiplication. These vector embeddings are then processed by a transformer encoder as if they were token embeddings.
Applications of machine learning in earth sciences include geological mapping, gas leakage detection and geological features identification. Machine learning (ML) is a type of artificial intelligence (AI) that enables computer systems to classify, cluster, identify and analyze vast and complex sets of data while eliminating the need for explicit instructions and programming. Earth science is the study of the origin, evolution, and future of the planet Earth. The Earth system can be subdivided into four major components including the solid earth, atmosphere, hydrosphere and biosphere.



