Distributions, also known as Schwartz distributions or generalized functions, are objects that generalize the classical notion of functions in mathematical analysis. Distributions make it possible to differentiate functions whose derivatives do not exist in the classical sense. In particular, any locally integrable function has a distributional derivative.

The stress–energy tensor, sometimes called the stress–energy–momentum tensor or the energy–momentum tensor, is a tensor physical quantity that describes the density and flux of energy and momentum in spacetime, generalizing the stress tensor of Newtonian physics. It is an attribute of matter, radiation, and non-gravitational force fields. This density and flux of energy and momentum are the sources of the gravitational field in the Einstein field equations of general relativity, just as mass density is the source of such a field in Newtonian gravity.

The method of least squares is a parameter estimation method in regression analysis based on minimizing the sum of the squares of the residuals made in the results of each individual equation.
In mechanics and geometry, the 3D rotation group, often denoted SO(3), is the group of all rotations about the origin of three-dimensional Euclidean space under the operation of composition.
In the calculus of variations, a field of mathematical analysis, the functional derivative relates a change in a functional to a change in a function on which the functional depends.
In physics, the S-matrix or scattering matrix relates the initial state and the final state of a physical system undergoing a scattering process. It is used in quantum mechanics, scattering theory and quantum field theory (QFT).

In quantum mechanics and quantum field theory, the propagator is a function that specifies the probability amplitude for a particle to travel from one place to another in a given period of time, or to travel with a certain energy and momentum. In Feynman diagrams, which serve to calculate the rate of collisions in quantum field theory, virtual particles contribute their propagator to the rate of the scattering event described by the respective diagram. Propagators may also be viewed as the inverse of the wave operator appropriate to the particle, and are, therefore, often called (causal) Green's functions.
In quantum mechanics, information theory, and Fourier analysis, the entropic uncertainty or Hirschman uncertainty is defined as the sum of the temporal and spectral Shannon entropies. It turns out that Heisenberg's uncertainty principle can be expressed as a lower bound on the sum of these entropies. This is stronger than the usual statement of the uncertainty principle in terms of the product of standard deviations.

In probability theory, a distribution is said to be stable if a linear combination of two independent random variables with this distribution has the same distribution, up to location and scale parameters. A random variable is said to be stable if its distribution is stable. The stable distribution family is also sometimes referred to as the Lévy alpha-stable distribution, after Paul Lévy, the first mathematician to have studied it.

In mathematics, a differentiable manifold is a type of manifold that is locally similar enough to a vector space to allow one to apply calculus. Any manifold can be described by a collection of charts (atlas). One may then apply ideas from calculus while working within the individual charts, since each chart lies within a vector space to which the usual rules of calculus apply. If the charts are suitably compatible, then computations done in one chart are valid in any other differentiable chart.
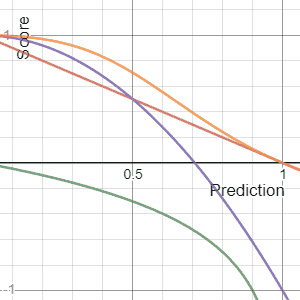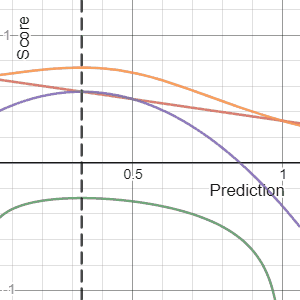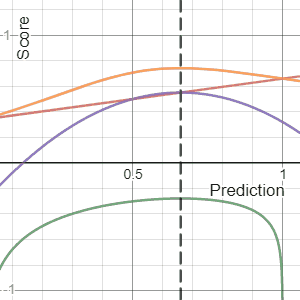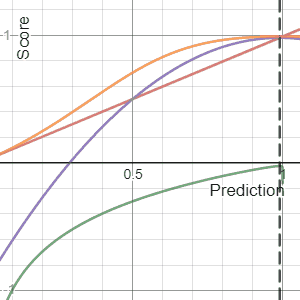
In decision theory, a scoring rule provides evaluation metrics for probabilistic predictions or forecasts. While "regular" loss functions assign a goodness-of-fit score to a predicted value and an observed value, scoring rules assign such a score to a predicted probability distribution and an observed value. On the other hand, a scoring function provides a summary measure for the evaluation of point predictions, i.e. one predicts a property or functional , like the expectation or the median.
In economics, discrete choice models, or qualitative choice models, describe, explain, and predict choices between two or more discrete alternatives, such as entering or not entering the labor market, or choosing between modes of transport. Such choices contrast with standard consumption models in which the quantity of each good consumed is assumed to be a continuous variable. In the continuous case, calculus methods can be used to determine the optimum amount chosen, and demand can be modeled empirically using regression analysis. On the other hand, discrete choice analysis examines situations in which the potential outcomes are discrete, such that the optimum is not characterized by standard first-order conditions. Thus, instead of examining "how much" as in problems with continuous choice variables, discrete choice analysis examines "which one". However, discrete choice analysis can also be used to examine the chosen quantity when only a few distinct quantities must be chosen from, such as the number of vehicles a household chooses to own and the number of minutes of telecommunications service a customer decides to purchase. Techniques such as logistic regression and probit regression can be used for empirical analysis of discrete choice.
The Newman–Penrose (NP) formalism is a set of notation developed by Ezra T. Newman and Roger Penrose for general relativity (GR). Their notation is an effort to treat general relativity in terms of spinor notation, which introduces complex forms of the usual variables used in GR. The NP formalism is itself a special case of the tetrad formalism, where the tensors of the theory are projected onto a complete vector basis at each point in spacetime. Usually this vector basis is chosen to reflect some symmetry of the spacetime, leading to simplified expressions for physical observables. In the case of the NP formalism, the vector basis chosen is a null tetrad: a set of four null vectors—two real, and a complex-conjugate pair. The two real members often asymptotically point radially inward and radially outward, and the formalism is well adapted to treatment of the propagation of radiation in curved spacetime. The Weyl scalars, derived from the Weyl tensor, are often used. In particular, it can be shown that one of these scalars— in the appropriate frame—encodes the outgoing gravitational radiation of an asymptotically flat system.
In mathematics and mathematical physics, raising and lowering indices are operations on tensors which change their type. Raising and lowering indices are a form of index manipulation in tensor expressions.
An -superprocess, , within mathematics probability theory is a stochastic process on that is usually constructed as a special limit of near-critical branching diffusions.
In statistics, the variance function is a smooth function that depicts the variance of a random quantity as a function of its mean. The variance function is a measure of heteroscedasticity and plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.
Bayesian hierarchical modelling is a statistical model written in multiple levels that estimates the parameters of the posterior distribution using the Bayesian method. The sub-models combine to form the hierarchical model, and Bayes' theorem is used to integrate them with the observed data and account for all the uncertainty that is present. The result of this integration is the posterior distribution, also known as the updated probability estimate, as additional evidence on the prior distribution is acquired.
The generalized functional linear model (GFLM) is an extension of the generalized linear model (GLM) that allows one to regress univariate responses of various types on functional predictors, which are mostly random trajectories generated by a square-integrable stochastic processes. Similarly to GLM, a link function relates the expected value of the response variable to a linear predictor, which in case of GFLM is obtained by forming the scalar product of the random predictor function with a smooth parameter function . Functional Linear Regression, Functional Poisson Regression and Functional Binomial Regression, with the important Functional Logistic Regression included, are special cases of GFLM. Applications of GFLM include classification and discrimination of stochastic processes and functional data.
Pure inductive logic (PIL) is the area of mathematical logic concerned with the philosophical and mathematical foundations of probabilistic inductive reasoning. It combines classical predicate logic and probability theory. Probability values are assigned to sentences of a first-order relational language to represent degrees of belief that should be held by a rational agent. Conditional probability values represent degrees of belief based on the assumption of some received evidence.
This article summarizes several identities in exterior calculus, a mathematical notation used in differential geometry.



































