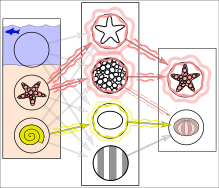
In digital image processing and computer vision, image segmentation is the process of partitioning a digital image into multiple image segments, also known as image regions or image objects. The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze. Image segmentation is typically used to locate objects and boundaries in images. More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.
Template matching is a technique in digital image processing for finding small parts of an image which match a template image. It can be used for quality control in manufacturing, navigation of mobile robots, or edge detection in images.

Deep learning is the subset of machine learning methods which are based on artificial neural networks with representation learning. The adjective "deep" in deep learning refers to the use of multiple layers in the network. Methods used can be either supervised, semi-supervised or unsupervised.

The MNIST database is a large database of handwritten digits that is commonly used for training various image processing systems. The database is also widely used for training and testing in the field of machine learning. It was created by "re-mixing" the samples from NIST's original datasets. The creators felt that since NIST's training dataset was taken from American Census Bureau employees, while the testing dataset was taken from American high school students, it was not well-suited for machine learning experiments. Furthermore, the black and white images from NIST were normalized to fit into a 28x28 pixel bounding box and anti-aliased, which introduced grayscale levels.

Convolutional neural network (CNN) is a regularized type of feed-forward neural network that learns feature engineering by itself via filters optimization. Vanishing gradients and exploding gradients, seen during backpropagation in earlier neural networks, are prevented by using regularized weights over fewer connections. For example, for each neuron in the fully-connected layer 10,000 weights would be required for processing an image sized 100 × 100 pixels. However, applying cascaded convolution kernels, only 25 neurons are required to process 5x5-sized tiles. Higher-layer features are extracted from wider context windows, compared to lower-layer features.

In computer vision, a saliency map is an image that highlights the region on which people's eyes focus first. The goal of a saliency map is to reflect the degree of importance of a pixel to the human visual system. For example, in this image, a person first looks at the fort and light clouds, so they should be highlighted on the saliency map. Saliency maps engineered in artificial or computer vision are typically not the same as the actual saliency map constructed by biological or natural vision.
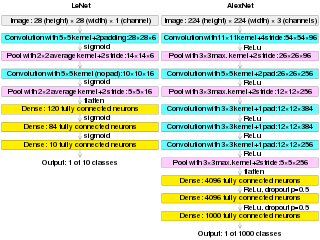
AlexNet is the name of a convolutional neural network (CNN) architecture, designed by Alex Krizhevsky in collaboration with Ilya Sutskever and Geoffrey Hinton, who was Krizhevsky's Ph.D. advisor at the University of Toronto.
The CIFAR-10 dataset is a collection of images that are commonly used to train machine learning and computer vision algorithms. It is one of the most widely used datasets for machine learning research. The CIFAR-10 dataset contains 60,000 32x32 color images in 10 different classes. The 10 different classes represent airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks. There are 6,000 images of each class.
Neural architecture search (NAS) is a technique for automating the design of artificial neural networks (ANN), a widely used model in the field of machine learning. NAS has been used to design networks that are on par or outperform hand-designed architectures. Methods for NAS can be categorized according to the search space, search strategy and performance estimation strategy used:
U-Net is a convolutional neural network that was developed for biomedical image segmentation at the Computer Science Department of the University of Freiburg. The network is based on a fully convolutional neural network whose architecture was modified and extended to work with fewer training images and to yield more precise segmentation. Segmentation of a 512 × 512 image takes less than a second on a modern GPU.
A Siamese neural network is an artificial neural network that uses the same weights while working in tandem on two different input vectors to compute comparable output vectors. Often one of the output vectors is precomputed, thus forming a baseline against which the other output vector is compared. This is similar to comparing fingerprints but can be described more technically as a distance function for locality-sensitive hashing.
An event camera, also known as a neuromorphic camera, silicon retina or dynamic vision sensor, is an imaging sensor that responds to local changes in brightness. Event cameras do not capture images using a shutter as conventional (frame) cameras do. Instead, each pixel inside an event camera operates independently and asynchronously, reporting changes in brightness as they occur, and staying silent otherwise.
In the domain of physics and probability, the filters, random fields, and maximum entropy (FRAME) model is a Markov random field model of stationary spatial processes, in which the energy function is the sum of translation-invariant potential functions that are one-dimensional non-linear transformations of linear filter responses. The FRAME model was originally developed by Song-Chun Zhu, Ying Nian Wu, and David Mumford for modeling stochastic texture patterns, such as grasses, tree leaves, brick walls, water waves, etc. This model is the maximum entropy distribution that reproduces the observed marginal histograms of responses from a bank of filters, where for each filter tuned to a specific scale and orientation, the marginal histogram is pooled over all the pixels in the image domain. The FRAME model is also proved to be equivalent to the micro-canonical ensemble, which was named the Julesz ensemble. Gibbs sampler is adopted to synthesize texture images by drawing samples from the FRAME model.

Video super-resolution (VSR) is the process of generating high-resolution video frames from the given low-resolution video frames. Unlike single-image super-resolution (SISR), the main goal is not only to restore more fine details while saving coarse ones, but also to preserve motion consistency.
Self-supervised learning (SSL) is a paradigm in machine learning where a model is trained on a task using the data itself to generate supervisory signals, rather than relying on external labels provided by humans. In the context of neural networks, self-supervised learning aims to leverage inherent structures or relationships within the input data to create meaningful training signals. SSL tasks are designed so that solving it requires capturing essential features or relationships in the data. The input data is typically augmented or transformed in a way that creates pairs of related samples. One sample serves as the input, and the other is used to formulate the supervisory signal. This augmentation can involve introducing noise, cropping, rotation, or other transformations. Self-supervised learning more closely imitates the way humans learn to classify objects.
A vision transformer (ViT) is a transformer designed for computer vision. Transformers were introduced in 2017, and have found widespread use in natural language processing. In 2020, they were adapted for computer vision, yielding ViT. The basic structure is to break down input images as a series of patches, then tokenized, before applying the tokens to a standard Transformer architecture.
Small object detection is a particular case of object detection where various techniques are employed to detect small objects in digital images and videos. "Small objects" are objects having a small pixel footprint in the input image. In areas such as aerial imagery, state-of-the-art object detection techniques under performed because of small objects.
Xiaoming Liu is a Chinese-American computer scientist and an academic. He is a Professor in the Department of Computer Science and Engineering, MSU Foundation Professor as well as Anil K. and Nandita Jain Endowed Professor of Engineering at Michigan State University.