
The Great Internet Mersenne Prime Search (GIMPS) is a collaborative project of volunteers who use freely available software to search for Mersenne prime numbers.

A supercomputer is a computer with a high level of performance as compared to a general-purpose computer. The performance of a supercomputer is commonly measured in floating-point operations per second (FLOPS) instead of million instructions per second (MIPS). Since 2017, supercomputers have existed which can perform over 1017 FLOPS (a hundred quadrillion FLOPS, 100 petaFLOPS or 100 PFLOPS). For comparison, a desktop computer has performance in the range of hundreds of gigaFLOPS (1011) to tens of teraFLOPS (1013). Since November 2017, all of the world's fastest 500 supercomputers run on Linux-based operating systems. Additional research is being conducted in the United States, the European Union, Taiwan, Japan, and China to build faster, more powerful and technologically superior exascale supercomputers.
Grid computing is the use of widely distributed computer resources to reach a common goal. A computing grid can be thought of as a distributed system with non-interactive workloads that involve many files. Grid computing is distinguished from conventional high-performance computing systems such as cluster computing in that grid computers have each node set to perform a different task/application. Grid computers also tend to be more heterogeneous and geographically dispersed than cluster computers. Although a single grid can be dedicated to a particular application, commonly a grid is used for a variety of purposes. Grids are often constructed with general-purpose grid middleware software libraries. Grid sizes can be quite large.
In computing, floating point operations per second is a measure of computer performance, useful in fields of scientific computations that require floating-point calculations. For such cases, it is a more accurate measure than measuring instructions per second.

High-performance computing (HPC) uses supercomputers and computer clusters to solve advanced computation problems.

TeraGrid was an e-Science grid computing infrastructure combining resources at eleven partner sites. The project started in 2001 and operated from 2004 through 2011.

Volunteer computing is a type of distributed computing in which people donate their computers' unused resources to a research-oriented project, and sometimes in exchange for credit points. The fundamental idea behind it is that a modern desktop computer is sufficiently powerful to perform billions of operations a second, but for most users only between 10–15% of its capacity is used. Common tasks such as word processing or web browsing leave the computer mostly idle.
In computer science, high-throughput computing (HTC) is the use of many computing resources over long periods of time to accomplish a computational task.

A computer cluster is a set of computers that work together so that they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software. The newest manifestation of cluster computing is cloud computing.
Many-task computing (MTC) in computational science is an approach to parallel computing that aims to bridge the gap between two computing paradigms: high-throughput computing (HTC) and high-performance computing (HPC).

Distributed European Infrastructure for Supercomputing Applications (DEISA) was a consortium of major national supercomputing centres in Europe. Initiated in 2002, it became a European Union funded supercomputer project. The consortium of eleven national supercomputing centres from seven European countries promoted pan-European research on European high-performance computing systems by creating a European collaborative environment in the area of supercomputing.
The Swiss National Supercomputing Centre is the national high-performance computing centre of Switzerland. It was founded in Manno, canton Ticino, in 1991. In March 2012, the CSCS moved to its new location in Lugano-Cornaredo.
Supercomputing in India has a history going back to the 1980s. The Government of India created an indigenous development programme as they had difficulty purchasing foreign supercomputers. As of June 2023, the AIRAWAT supercomputer is the fastest supercomputer in India, having been ranked 75th fastest in the world in the TOP500 supercomputer list. AIRAWAT has been installed at the Centre for Development of Advanced Computing (C-DAC) in Pune.

Several centers for supercomputing exist across Europe, and distributed access to them is coordinated by European initiatives to facilitate high-performance computing. One such initiative, the HPC Europa project, fits within the Distributed European Infrastructure for Supercomputing Applications (DEISA), which was formed in 2002 as a consortium of eleven supercomputing centers from seven European countries. Operating within the CORDIS framework, HPC Europa aims to provide access to supercomputers across Europe.
The QosCosGrid is a quasi-opportunistic supercomputing system using grid computing.
Approaches to supercomputer architecture have taken dramatic turns since the earliest systems were introduced in the 1960s. Early supercomputer architectures pioneered by Seymour Cray relied on compact innovative designs and local parallelism to achieve superior computational peak performance. However, in time the demand for increased computational power ushered in the age of massively parallel systems.

Francine Berman is an American computer scientist, and a leader in digital data preservation and cyber-infrastructure. In 2009, she was the inaugural recipient of the IEEE/ACM-CS Ken Kennedy Award "for her influential leadership in the design, development and deployment of national-scale cyberinfrastructure, her inspiring work as a teacher and mentor, and her exemplary service to the high performance community". In 2004, Business Week called her the "reigning teraflop queen".
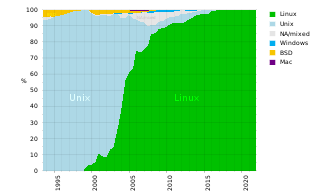
A supercomputer operating system is an operating system intended for supercomputers. Since the end of the 20th century, supercomputer operating systems have undergone major transformations, as fundamental changes have occurred in supercomputer architecture. While early operating systems were custom tailored to each supercomputer to gain speed, the trend has been moving away from in-house operating systems and toward some form of Linux, with it running all the supercomputers on the TOP500 list in November 2017. In 2021, top 10 computers run for instance Red Hat Enterprise Linux (RHEL), or some variant of it or other Linux distribution e.g. Ubuntu.
Massively parallel is the term for using a large number of computer processors to simultaneously perform a set of coordinated computations in parallel. GPUs are massively parallel architecture with tens of thousands of threads.
Message passing is an inherent element of all computer clusters. All computer clusters, ranging from homemade Beowulfs to some of the fastest supercomputers in the world, rely on message passing to coordinate the activities of the many nodes they encompass. Message passing in computer clusters built with commodity servers and switches is used by virtually every internet service.


