Related Research Articles

In molecular biology, a transcription factor (TF) is a protein that controls the rate of transcription of genetic information from DNA to messenger RNA, by binding to a specific DNA sequence. The function of TFs is to regulate—turn on and off—genes in order to make sure that they are expressed in the desired cells at the right time and in the right amount throughout the life of the cell and the organism. Groups of TFs function in a coordinated fashion to direct cell division, cell growth, and cell death throughout life; cell migration and organization during embryonic development; and intermittently in response to signals from outside the cell, such as a hormone. There are approximately 1600 TFs in the human genome. Transcription factors are members of the proteome as well as regulome.
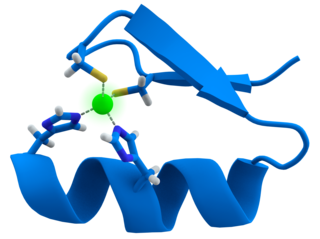
A zinc finger is a small protein structural motif that is characterized by the coordination of one or more zinc ions (Zn2+) which stabilizes the fold. It was originally coined to describe the finger-like appearance of a hypothesized structure from the African clawed frog (Xenopus laevis) transcription factor IIIA. However, it has been found to encompass a wide variety of differing protein structures in eukaryotic cells. Xenopus laevis TFIIIA was originally demonstrated to contain zinc and require the metal for function in 1983, the first such reported zinc requirement for a gene regulatory protein followed soon thereafter by the Krüppel factor in Drosophila. It often appears as a metal-binding domain in multi-domain proteins.

Histone acetyltransferases (HATs) are enzymes that acetylate conserved lysine amino acids on histone proteins by transferring an acetyl group from acetyl-CoA to form ε-N-acetyllysine. DNA is wrapped around histones, and, by transferring an acetyl group to the histones, genes can be turned on and off. In general, histone acetylation increases gene expression.

DNA-binding proteins are proteins that have DNA-binding domains and thus have a specific or general affinity for single- or double-stranded DNA. Sequence-specific DNA-binding proteins generally interact with the major groove of B-DNA, because it exposes more functional groups that identify a base pair.

SR proteins are a conserved family of proteins involved in RNA splicing. SR proteins are named because they contain a protein domain with long repeats of serine and arginine amino acid residues, whose standard abbreviations are "S" and "R" respectively. SR proteins are ~200-600 amino acids in length and composed of two domains, the RNA recognition motif (RRM) region and the RS domain. SR proteins are more commonly found in the nucleus than the cytoplasm, but several SR proteins are known to shuttle between the nucleus and the cytoplasm.
RNA-binding proteins are proteins that bind to the double or single stranded RNA in cells and participate in forming ribonucleoprotein complexes. RBPs contain various structural motifs, such as RNA recognition motif (RRM), dsRNA binding domain, zinc finger and others. They are cytoplasmic and nuclear proteins. However, since most mature RNA is exported from the nucleus relatively quickly, most RBPs in the nucleus exist as complexes of protein and pre-mRNA called heterogeneous ribonucleoprotein particles (hnRNPs). RBPs have crucial roles in various cellular processes such as: cellular function, transport and localization. They especially play a major role in post-transcriptional control of RNAs, such as: splicing, polyadenylation, mRNA stabilization, mRNA localization and translation. Eukaryotic cells express diverse RBPs with unique RNA-binding activity and protein–protein interaction. According to the Eukaryotic RBP Database (EuRBPDB), there are 2961 genes encoding RBPs in humans. During evolution, the diversity of RBPs greatly increased with the increase in the number of introns. Diversity enabled eukaryotic cells to utilize RNA exons in various arrangements, giving rise to a unique RNP (ribonucleoprotein) for each RNA. Although RBPs have a crucial role in post-transcriptional regulation in gene expression, relatively few RBPs have been studied systematically.It has now become clear that RNA–RBP interactions play important roles in many biological processes among organisms.
A DNA-binding domain (DBD) is an independently folded protein domain that contains at least one structural motif that recognizes double- or single-stranded DNA. A DBD can recognize a specific DNA sequence or have a general affinity to DNA. Some DNA-binding domains may also include nucleic acids in their folded structure.
Therapeutic gene modulation refers to the practice of altering the expression of a gene at one of various stages, with a view to alleviate some form of ailment. It differs from gene therapy in that gene modulation seeks to alter the expression of an endogenous gene whereas gene therapy concerns the introduction of a gene whose product aids the recipient directly.
Cleavage and polyadenylation specificity factor (CPSF) is involved in the cleavage of the 3' signaling region from a newly synthesized pre-messenger RNA (pre-mRNA) molecule in the process of gene transcription. In eukaryotes, messenger RNA precursors (pre-mRNA) are transcribed in the nucleus from DNA by the enzyme, RNA polymerase II. The pre-mRNA must undergo post-transcriptional modifications, forming mature RNA (mRNA), before they can be transported into the cytoplasm for translation into proteins. The post-transcriptional modifications are: the addition of a 5' m7G cap, splicing of intronic sequences, and 3' cleavage and polyadenylation.
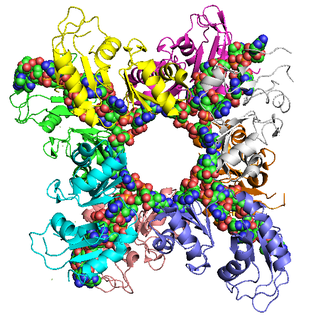
Poly(A)-binding protein is an RNA-binding protein which triggers the binding of eukaryotic initiation factor 4 complex (eIF4G) directly to the poly(A) tail of mRNA which is 200-250 nucleotides long. The poly(A) tail is located on the 3' end of mRNA and was discovered by Mary Edmonds, who also characterized the poly-A polymerase enzyme that generates the poly(a) tail. The binding protein is also involved in mRNA precursors by helping polyadenylate polymerase add the poly(A) nucleotide tail to the pre-mRNA before translation. The nuclear isoform selectively binds to around 50 nucleotides and stimulates the activity of polyadenylate polymerase by increasing its affinity towards RNA. Poly(A)-binding protein is also present during stages of mRNA metabolism including nonsense-mediated decay and nucleocytoplasmic trafficking. The poly(A)-binding protein may also protect the tail from degradation and regulate mRNA production. Without these two proteins in-tandem, then the poly(A) tail would not be added and the RNA would degrade quickly.

The signal recognition particle RNA, is part of the signal recognition particle (SRP) ribonucleoprotein complex. SRP recognizes the signal peptide and binds to the ribosome, halting protein synthesis. SRP-receptor is a protein that is embedded in a membrane, and which contains a transmembrane pore. When the SRP-ribosome complex binds to SRP-receptor, SRP releases the ribosome and drifts away. The ribosome resumes protein synthesis, but now the protein is moving through the SRP-receptor transmembrane pore.

Synaptotagmin-binding, cytoplasmic RNA-interacting protein (SYNCRIP), also known as heterogeneous nuclear ribonucleoprotein (hnRNP) Q or NS1-associated protein-1 (NSAP-1), is a protein that in humans is encoded by the SYNCRIP gene. As the name implies, SYNCRIP is localized predominantly in the cytoplasm. It is evolutionarily conserved across eukaryotes and participates in several cellular and disease pathways, especially in neuronal and muscular development. In humans, there are three isoforms, all of which are associated in vitro with pre-mRNAs, mRNA splicing intermediates, and mature mRNA-protein complexes, including mRNA turnover.
RNA-binding protein 4 is a protein that in humans is encoded by the RBM4 gene.
Zinc finger protein chimera are chimeric proteins composed of a DNA-binding zinc finger protein domain and another domain through which the protein exerts its effect. The effector domain may be a transcriptional activator (A) or repressor (R), a methylation domain (M) or a nuclease (N).

RNA recognition motif, RNP-1 is a putative RNA-binding domain of about 90 amino acids that are known to bind single-stranded RNAs. It was found in many eukaryotic proteins.
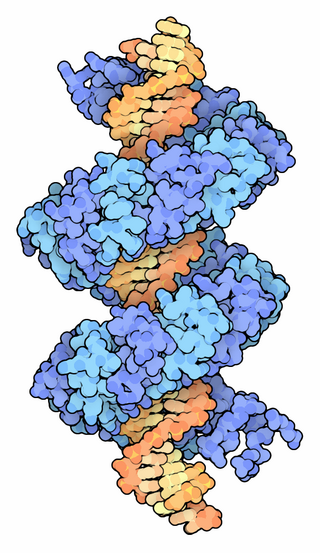
TALeffectors are proteins secreted by some β- and γ-proteobacteria. Most of these are Xanthomonads. Plant pathogenic Xanthomonas bacteria are especially known for TALEs, produced via their type III secretion system. These proteins can bind promoter sequences in the host plant and activate the expression of plant genes that aid bacterial infection. The TALE domain responsible for binding to DNA is known to have 1.5 to 33.5 short sequences that are repeated multiple times. Each of these repeats was found to be specific for a certain base pair of the DNA. These repeats also have repeat variable residues (RVD) that can detect specific DNA base pairs. They recognize plant DNA sequences through a central repeat domain consisting of a variable number of ~34 amino acid repeats. There appears to be a one-to-one correspondence between the identity of two critical amino acids in each repeat and each DNA base in the target sequence. These proteins are interesting to researchers both for their role in disease of important crop species and the relative ease of retargeting them to bind new DNA sequences. Similar proteins can be found in the pathogenic bacterium Ralstonia solanacearum and Burkholderia rhizoxinica, as well as yet unidentified marine microorganisms. The term TALE-likes is used to refer to the putative protein family encompassing the TALEs and these related proteins.
Zinc finger transcription factors or ZF-TFs, are transcription factors composed of a zinc finger-binding domain and any of a variety of transcription-factor effector-domains that exert their modulatory effect in the vicinity of any sequence to which the protein domain binds.

The WRKY domain is found in the WRKY transcription factor family, a class of transcription factors. The WRKY domain is found almost exclusively in plants although WRKY genes appear present in some diplomonads, social amoebae and other amoebozoa, and fungi incertae sedis. They appear absent in other non-plant species. WRKY transcription factors have been a significant area of plant research for the past 20 years. The WRKY DNA-binding domain recognizes the W-box (T)TGAC(C/T) cis-regulatory element.

Archaeal transcription factor B is a protein family of extrinsic transcription factors that guide the initiation of RNA transcription in organisms that fall under the domain of Archaea. It is homologous to eukaryotic TFIIB and, more distantly, to bacterial sigma factor. Like these proteins, it is involved in forming transcription preinitiation complexes. Its structure includes several conserved motifs which interact with DNA and other transcription factors, notably the single type of RNA polymerase that performs transcription in Archaea.

Zinc finger protein 226 is a protein that in humans is encoded by the ZNF226 gene.
References
- ↑ Cook, Kate B.; Kazan, Hilal (2010). "RBPDB: a database of RNA-binding specificities". Nucleic Acids Research . 39 (Database issue). Oxford University Press: D301–D308. doi:10.1093/nar/gkq1069. PMC 3013675 . PMID 21036867.
- ↑ "RBPDB: The database of RNA-binding specificities". rbpdb.ccbr.utoronto.ca. Retrieved 29 April 2021.
- ↑ Matera, A. Gregory; Terns, Rebecca M.; Terns, Michael P. (March 2007). "Non-coding RNAs: lessons from the small nuclear and small nucleolar RNAs". Nature Reviews Molecular Cell Biology . 8 (3). Nature Publishing Group: 209–220. doi:10.1038/nrm2124. PMID 17318225. S2CID 30268055.
- ↑ Glisovic, Tina; Bachorik, Jennifer L. (2008). "RNA-binding proteins and post-transcriptional gene regulation". FEBS Letters . 582 (14). Elsevier B.V.: 1977–1986. Bibcode:2008FEBSL.582.1977G. doi:10.1016/j.febslet.2008.03.004. PMC 2858862 . PMID 18342629.
- ↑ Kishore, Shivendra; Luber, Sandra; Zavolan, Mihaela (2010). "Deciphering the role of RNA-binding proteins in the post-transcriptional control of gene expression". Briefings in Functional Genomics . 9 (5–6): 391–404. doi:10.1093/bfgp/elq028. PMC 3080770 . PMID 21127008.
- ↑ Chen, Y.; Varani, G. (2005). "Protein families and RNA recognition". FEBS J. 272 (9): 2088–2097. doi:10.1111/j.1742-4658.2005.04650.x. PMID 15853794. S2CID 12432954.
- 1 2 3 4 5 Lunde, B.M.; Moore, C.; Varani, G. (2007). "RNA-binding proteins: modular design for efficient function". Nat. Rev. Mol. Cell Biol. 8 (6): 479–490. doi:10.1038/nrm2178. PMC 5507177 . PMID 17473849.
- ↑ Hogan, DJ; Riordan, DP (2008). "Diverse RNA-binding proteins interact with functionally related sets of RNAs, suggesting an extensive regulatory system". PLOS Biology . 6 (10): 2297–2313. doi: 10.1371/journal.pbio.0060255 . PMC 2573929 . PMID 18959479.
- ↑ Swanson MS, Dreyfuss G, Pinol-Roma S (1988). "Heterogeneous nuclear ribonucleoprotein particles and the pathway of mRNA formation". Trends Biochem. Sci. 13 (3): 86–91. doi:10.1016/0968-0004(88)90046-1. PMID 3072706.
- ↑ García-Mayoral MF, Hollingworth D, Masino L, et al. (April 2007). "The structure of the C-terminal KH domains of KSRP reveals a noncanonical motif important for mRNA degradation" (PDF). Structure. 15 (4): 485–98. doi:10.1016/j.str.2007.03.006. PMID 17437720.
- ↑ Klug A, Rhodes D (1987). "Zinc fingers: a novel protein fold for nucleic acid recognition". Cold Spring Harb. Symp. Quant. Biol. 52: 473–82. doi:10.1101/sqb.1987.052.01.054. PMID 3135979.
- ↑ Ray, D.; Kazan, H. (2013). "A compendiumof RNA-binding motifs for decoding gene regulation". Nature . 499 (7457): 172–177. Bibcode:2013Natur.499..172R. doi:10.1038/nature12311. PMC 3929597 . PMID 23846655.