Bell's theorem is a term encompassing a number of closely related results in physics, all of which determine that quantum mechanics is incompatible with local hidden-variable theories, given some basic assumptions about the nature of measurement. "Local" here refers to the principle of locality, the idea that a particle can only be influenced by its immediate surroundings, and that interactions mediated by physical fields cannot propagate faster than the speed of light. "Hidden variables" are putative properties of quantum particles that are not included in quantum theory but nevertheless affect the outcome of experiments. In the words of physicist John Stewart Bell, for whom this family of results is named, "If [a hidden-variable theory] is local it will not agree with quantum mechanics, and if it agrees with quantum mechanics it will not be local."
An odds ratio (OR) is a statistic that quantifies the strength of the association between two events, A and B. The odds ratio is defined as the ratio of the odds of A in the presence of B and the odds of A in the absence of B, or equivalently, the ratio of the odds of B in the presence of A and the odds of B in the absence of A. Two events are independent if and only if the OR equals 1, i.e., the odds of one event are the same in either the presence or absence of the other event. If the OR is greater than 1, then A and B are associated (correlated) in the sense that, compared to the absence of B, the presence of B raises the odds of A, and symmetrically the presence of A raises the odds of B. Conversely, if the OR is less than 1, then A and B are negatively correlated, and the presence of one event reduces the odds of the other event.

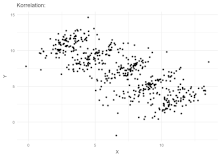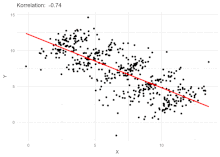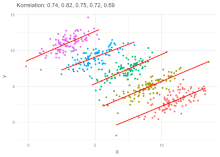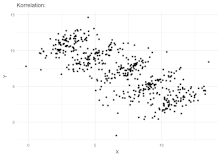
In statistics, a spurious relationship or spurious correlation is a mathematical relationship in which two or more events or variables are associated but not causally related, due to either coincidence or the presence of a certain third, unseen factor.

Data dredging is the misuse of data analysis to find patterns in data that can be presented as statistically significant, thus dramatically increasing and understating the risk of false positives. This is done by performing many statistical tests on the data and only reporting those that come back with significant results.
Linear discriminant analysis (LDA), normal discriminant analysis (NDA), or discriminant function analysis is a generalization of Fisher's linear discriminant, a method used in statistics and other fields, to find a linear combination of features that characterizes or separates two or more classes of objects or events. The resulting combination may be used as a linear classifier, or, more commonly, for dimensionality reduction before later classification.
In statistics, econometrics, epidemiology and related disciplines, the method of instrumental variables (IV) is used to estimate causal relationships when controlled experiments are not feasible or when a treatment is not successfully delivered to every unit in a randomized experiment. Intuitively, IVs are used when an explanatory variable of interest is correlated with the error term (endogenous), in which case ordinary least squares and ANOVA give biased results. A valid instrument induces changes in the explanatory variable but has no independent effect on the dependent variable and is not correlated with the error term, allowing a researcher to uncover the causal effect of the explanatory variable on the dependent variable.

The Granger causality test is a statistical hypothesis test for determining whether one time series is useful in forecasting another, first proposed in 1969. Ordinarily, regressions reflect "mere" correlations, but Clive Granger argued that causality in economics could be tested for by measuring the ability to predict the future values of a time series using prior values of another time series. Since the question of "true causality" is deeply philosophical, and because of the post hoc ergo propter hoc fallacy of assuming that one thing preceding another can be used as a proof of causation, econometricians assert that the Granger test finds only "predictive causality". Using the term "causality" alone is a misnomer, as Granger-causality is better described as "precedence", or, as Granger himself later claimed in 1977, "temporally related". Rather than testing whether Xcauses Y, the Granger causality tests whether X forecastsY.
This glossary of statistics and probability is a list of definitions of terms and concepts used in the mathematical sciences of statistics and probability, their sub-disciplines, and related fields. For additional related terms, see Glossary of mathematics and Glossary of experimental design.
In causal inference, a confounder is a variable that influences both the dependent variable and independent variable, causing a spurious association. Confounding is a causal concept, and as such, cannot be described in terms of correlations or associations. The existence of confounders is an important quantitative explanation why correlation does not imply causation. Some notations are explicitly designed to identify the existence, possible existence, or non-existence of confounders in causal relationships between elements of a system.
In information theory, information dimension is an information measure for random vectors in Euclidean space, based on the normalized entropy of finely quantized versions of the random vectors. This concept was first introduced by Alfréd Rényi in 1959.

In the philosophy of science, a causal model is a conceptual model that describes the causal mechanisms of a system. Several types of causal notation may be used in the development of a causal model. Causal models can improve study designs by providing clear rules for deciding which independent variables need to be included/controlled for.
In the statistical analysis of observational data, propensity score matching (PSM) is a statistical matching technique that attempts to estimate the effect of a treatment, policy, or other intervention by accounting for the covariates that predict receiving the treatment. PSM attempts to reduce the bias due to confounding variables that could be found in an estimate of the treatment effect obtained from simply comparing outcomes among units that received the treatment versus those that did not. Paul R. Rosenbaum and Donald Rubin introduced the technique in 1983.

A plot is a graphical technique for representing a data set, usually as a graph showing the relationship between two or more variables. The plot can be drawn by hand or by a computer. In the past, sometimes mechanical or electronic plotters were used. Graphs are a visual representation of the relationship between variables, which are very useful for humans who can then quickly derive an understanding which may not have come from lists of values. Given a scale or ruler, graphs can also be used to read off the value of an unknown variable plotted as a function of a known one, but this can also be done with data presented in tabular form. Graphs of functions are used in mathematics, sciences, engineering, technology, finance, and other areas.
Isoline retrieval is a remote sensing inverse method that retrieves one or more isolines of a trace atmospheric constituent or variable. When used to validate another contour, it is the most accurate method possible for the task. When used to retrieve a whole field, it is a general, nonlinear inverse method and a robust estimator.
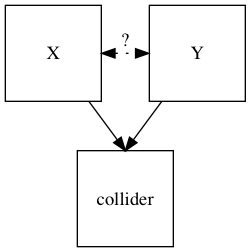
In statistics and causal graphs, a variable is a collider when it is causally influenced by two or more variables. The name "collider" reflects the fact that in graphical models, the arrow heads from variables that lead into the collider appear to "collide" on the node that is the collider. They are sometimes also referred to as inverted forks.
Causal inference is the process of determining the independent, actual effect of a particular phenomenon that is a component of a larger system. The main difference between causal inference and inference of association is that causal inference analyzes the response of an effect variable when a cause of the effect variable is changed. The study of why things occur is called etiology, and can be described using the language of scientific causal notation. Causal inference is said to provide the evidence of causality theorized by causal reasoning.
In statistics, Lord's paradox raises the issue of when it is appropriate to control for baseline status. In three papers, Frederic M. Lord gave examples when statisticians could reach different conclusions depending on whether they adjust for pre-existing differences. Holland & Rubin (1983) use these examples to illustrate how there may be multiple valid descriptive comparisons in the data, but causal conclusions require an underlying (untestable) causal model. Pearl used these examples to illustrate how graphical causal models resolve the issue of when control for baseline status is appropriate.
In statistics, econometrics, epidemiology, genetics and related disciplines, causal graphs are probabilistic graphical models used to encode assumptions about the data-generating process.
In statistics, linear regression is a statistical model which estimates the linear relationship between a scalar response and one or more explanatory variables. The case of one explanatory variable is called simple linear regression; for more than one, the process is called multiple linear regression. This term is distinct from multivariate linear regression, where multiple correlated dependent variables are predicted, rather than a single scalar variable. If the explanatory variables are measured with error then errors-in-variables models are required, also known as measurement error models.
Fairness in machine learning refers to the various attempts at correcting algorithmic bias in automated decision processes based on machine learning models. Decisions made by computers after a machine-learning process may be considered unfair if they were based on variables considered sensitive. For example gender, ethnicity, sexual orientation or disability. As it is the case with many ethical concepts, definitions of fairness and bias are always controversial. In general, fairness and bias are considered relevant when the decision process impacts people's lives. In machine learning, the problem of algorithmic bias is well known and well studied. Outcomes may be skewed by a range of factors and thus might be considered unfair with respect to certain groups or individuals. An example would be the way social media sites deliver personalized news to consumers.