
The Dublin Core, also known as the Dublin Core Metadata Element Set (DCMES), is a set of fifteen main metadata items for describing digital or physical resources. It was the first metadata standard for describing web content. The Dublin Core Metadata Initiative (DCMI) is responsible for formulating the Dublin Core; DCMI is a project of the Association for Information Science and Technology (ASIS&T), a non-profit organization.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
A Uniform Resource Identifier (URI) is a unique sequence of characters that identifies an abstract or physical resource, such as resources on a webpage, mail address, phone number, books, real-world objects such as people and places, concepts. URIs are used to identify anything described using the Resource Description Framework (RDF), for example, concepts that are part of an ontology defined using the Web Ontology Language (OWL), and people who are described using the Friend of a Friend vocabulary would each have an individual URI.
The Resource Description Framework (RDF) is a World Wide Web Consortium (W3C) standard originally designed as a data model for metadata. It has come to be used as a general method for description and exchange of graph data. RDF provides a variety of syntax notations and data serialization formats, with Turtle currently being the most widely used notation.
A Uniform Resource Name (URN) is a Uniform Resource Identifier (URI) that uses the urn scheme. URNs are globally unique persistent identifiers assigned within defined namespaces so they will be available for a long period of time, even after the resource which they identify ceases to exist or becomes unavailable. URNs cannot be used to directly locate an item and need not be resolvable, as they are simply templates that another parser may use to find an item.
REST is a software architectural style that was created to guide the design and development of the architecture for the World Wide Web. REST defines a set of constraints for how the architecture of a distributed, Internet-scale hypermedia system, such as the Web, should behave. The REST architectural style emphasises uniform interfaces, independent deployment of components, the scalability of interactions between them, and creating a layered architecture to promote caching to reduce user-perceived latency, enforce security, and encapsulate legacy systems.
The Internationalized Resource Identifier (IRI) is an internet protocol standard which builds on the Uniform Resource Identifier (URI) protocol by greatly expanding the set of permitted characters. It was defined by the Internet Engineering Task Force (IETF) in 2005 in RFC 3987. While URIs are limited to a subset of the US-ASCII character set, IRIs may additionally contain most characters from the Universal Character Set, including Chinese, Japanese, Korean, and Cyrillic characters.
A persistent uniform resource locator (PURL) is a uniform resource locator (URL) that is used to redirect to the location of the requested web resource. PURLs redirect HTTP clients using HTTP status codes.
In computer hypertext, a URI fragment is a string of characters that refers to a resource that is subordinate to another, primary resource. The primary resource is identified by a Uniform Resource Identifier (URI), and the fragment identifier points to the subordinate resource.
URL encoding, officially known as percent-encoding, is a method to encode arbitrary data in a uniform resource identifier (URI) using only the US-ASCII characters legal within a URI. Although it is known as URL encoding, it is also used more generally within the main Uniform Resource Identifier (URI) set, which includes both Uniform Resource Locator (URL) and Uniform Resource Name (URN). Consequently, it is also used in the preparation of data of the application/x-www-form-urlencoded media type, as is often used in the submission of HTML form data in HTTP requests.

URI normalization is the process by which URIs are modified and standardized in a consistent manner. The goal of the normalization process is to transform a URI into a normalized URI so it is possible to determine if two syntactically different URIs may be equivalent.
Gellish is an ontology language for data storage and communication, designed and developed by Andries van Renssen since mid-1990s. It started out as an engineering modeling language but evolved into a universal and extendable conceptual data modeling language with general applications. Because it includes domain-specific terminology and definitions, it is also a semantic data modelling language and the Gellish modeling methodology is a member of the family of semantic modeling methodologies.
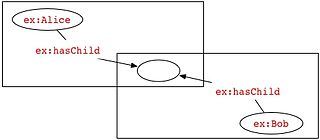
In RDF, a blank node is a node in an RDF graph representing a resource for which a URI or literal is not given. The resource represented by a blank node is also called an anonymous resource. According to the RDF standard a blank node can only be used as subject or object of an RDF triple.
The FAO geopolitical ontology is an ontology developed by the Food and Agriculture Organization of the United Nations (FAO) to describe, manage and exchange data related to geopolitical entities such as countries, territories, regions and other similar areas.

In computer science, information science and systems engineering, ontology engineering is a field which studies the methods and methodologies for building ontologies, which encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities of a given domain of interest. In a broader sense, this field also includes a knowledge construction of the domain using formal ontology representations such as OWL/RDF. A large-scale representation of abstract concepts such as actions, time, physical objects and beliefs would be an example of ontological engineering. Ontology engineering is one of the areas of applied ontology, and can be seen as an application of philosophical ontology. Core ideas and objectives of ontology engineering are also central in conceptual modeling.
The Handle System is the Corporation for National Research Initiatives's proprietary registry assigning persistent identifiers, or handles, to information resources, and for resolving "those handles into the information necessary to locate, access, and otherwise make use of the resources".

The HTTP Location header field is returned in responses from an HTTP server under two circumstances:
- To ask a web browser to load a different web page. In this circumstance, the Location header should be sent with an HTTP status code of 3xx. It is passed as part of the response by a web server when the requested URI has:
- To provide information about the location of a newly created resource. In this circumstance, the Location header should be sent with an HTTP status code of 201 or 202.

The geo URI scheme is a Uniform Resource Identifier (URI) scheme defined by the Internet Engineering Task Force's RFC 5870 as:
a Uniform Resource Identifier (URI) for geographic locations using the 'geo' scheme name. A 'geo' URI identifies a physical location in a two- or three-dimensional coordinate reference system in a compact, simple, human-readable, and protocol-independent way.
A uniform resource locator (URL), colloquially known as an address on the Web, is a reference to a resource that specifies its location on a computer network and a mechanism for retrieving it. A URL is a specific type of Uniform Resource Identifier (URI), although many people use the two terms interchangeably. URLs occur most commonly to reference web pages (HTTP/HTTPS) but are also used for file transfer (FTP), email (mailto), database access (JDBC), and many other applications.
A well-known URI is a Uniform Resource Identifier for URL path prefixes that start with /.well-known/. They are implemented in webservers so that requests to the servers for well-known services or information are available at URLs consistent well-known locations across servers.