One major practical drawback is its space complexity where d is the depth of the shallowest solution (the length of the shortest path from the source node to any given goal node) and b is the branching factor (the maximum number of successors for any given state). In practical travel-routing systems, it is generally outperformed by algorithms that can pre-process the graph to attain better performance,[2] as well as by memory-bounded approaches; however, A* is still the best solution in many cases.[3]
The A* algorithm terminates once it finds the shortest path to a specified goal, rather than generating the entire shortest-path tree from a specified source to all possible goals.
History
A* was invented by researchers working on Shakey the Robot's path planning.
A* was created as part of the Shakey project, which had the aim of building a mobile robot that could plan its own actions. Nils Nilsson originally proposed using the Graph Traverser algorithm[5] for Shakey's path planning.[6] Graph Traverser is guided by a heuristic function h(n), the estimated distance from node n to the goal node: it entirely ignores g(n), the distance from the start node to n. Bertram Raphael suggested using the sum, g(n) + h(n).[7] Peter Hart invented the concepts we now call admissibility and consistency of heuristic functions. A* was originally designed for finding least-cost paths when the cost of a path is the sum of its costs, but it has been shown that A* can be used to find optimal paths for any problem satisfying the conditions of a cost algebra.[8]
The original 1968 A* paper[4] contained a theorem stating that no A*-like algorithm[a] could expand fewer nodes than A* if the heuristic function is consistent and A*'s tie-breaking rule is suitably chosen. A "correction" was published a few years later[9] claiming that consistency was not required, but this was shown to be false in 1985 in Dechter and Pearl's definitive study of A*'s optimality (now called optimal efficiency), which gave an example of A* with a heuristic that was admissible but not consistent expanding arbitrarily more nodes than an alternative A*-like algorithm.[10]
Description
A* pathfinding algorithm navigating around a randomly-generated mazeIllustration of A* search for finding a path between two points on a graph. From left to right, a heuristic that prefers points closer to the goal is used increasingly.
A* is an informed search algorithm, or a best-first search, meaning that it is formulated in terms of weighted graphs: starting from a specific starting node of a graph, it aims to find a path to the given goal node having the smallest cost (least distance travelled, shortest time, etc.). It does this by maintaining a tree of paths originating at the start node and extending those paths one edge at a time until the goal node is reached.
At each iteration of its main loop, A* needs to determine which of its paths to extend. It does so based on the cost of the path and an estimate of the cost required to extend the path all the way to the goal. Specifically, A* selects the path that minimizes
where n is the next node on the path, g(n) is the cost of the path from the start node to n, and h(n) is a heuristic function that estimates the cost of the cheapest path from n to the goal. The heuristic function is problem-specific.
Typical implementations of A* use a priority queue to perform the repeated selection of minimum (estimated) cost nodes to expand. This priority queue is known as the open set, fringe or frontier. At each step of the algorithm, the node with the lowest f(x) value is removed from the queue, the f and g values of its neighbors are updated accordingly, and these neighbors are added to the queue. The algorithm continues until a removed node (thus the node with the lowest f value out of all fringe nodes) is a goal node.[b] The f value of that goal is then also the cost of the shortest path, since h at the goal is zero in an admissible heuristic.
The algorithm described so far only gives the length of the shortest path. To find the actual sequence of steps, the algorithm can be easily revised so that each node on the path keeps track of its predecessor. After this algorithm is run, the ending node will point to its predecessor, and so on, until some node's predecessor is the start node.
As an example, when searching for the shortest route on a map, h(x) might represent the straight-line distance to the goal, since that is physically the smallest possible distance between any two points. For a grid map from a video game, using the Taxicab distance or the Chebyshev distance becomes better depending on the set of movements available (4-way or 8-way).
If the heuristic h satisfies the additional condition h(x) ≤ d(x, y) + h(y) for every edge (x, y) of the graph (where d denotes the length of that edge), then h is called monotone, or consistent. With a consistent heuristic, A* is guaranteed to find an optimal path without processing any node more than once and A* is equivalent to running Dijkstra's algorithm with the reduced costd'(x, y) = d(x, y) + h(y) − h(x).[11]
functionreconstruct_path(cameFrom,current)total_path:={current}whilecurrentincameFrom.Keys:current:=cameFrom[current]total_path.prepend(current)returntotal_path// A* finds a path from start to goal.// h is the heuristic function. h(n) estimates the cost to reach goal from node n.functionA_Star(start,goal,h)// The set of discovered nodes that may need to be (re-)expanded.// Initially, only the start node is known.// This is usually implemented as a min-heap or priority queue rather than a hash-set.openSet:={start}// For node n, cameFrom[n] is the node immediately preceding it on the cheapest path from the start// to n currently known.cameFrom:=anemptymap// For node n, gScore[n] is the currently known cost of the cheapest path from start to n.gScore:=mapwithdefaultvalueofInfinitygScore[start]:=0// For node n, fScore[n] := gScore[n] + h(n). fScore[n] represents our current best guess as to// how cheap a path could be from start to finish if it goes through n.fScore:=mapwithdefaultvalueofInfinityfScore[start]:=h(start)whileopenSetisnotempty// This operation can occur in O(Log(N)) time if openSet is a min-heap or a priority queuecurrent:=thenodeinopenSethavingthelowestfScore[]valueifcurrent=goalreturnreconstruct_path(cameFrom,current)openSet.Remove(current)foreachneighborofcurrent// d(current,neighbor) is the weight of the edge from current to neighbor// tentative_gScore is the distance from start to the neighbor through currenttentative_gScore:=gScore[current]+d(current,neighbor)iftentative_gScore<gScore[neighbor]// This path to neighbor is better than any previous one. Record it!cameFrom[neighbor]:=currentgScore[neighbor]:=tentative_gScorefScore[neighbor]:=tentative_gScore+h(neighbor)ifneighbornotinopenSetopenSet.add(neighbor)// Open set is empty but goal was never reachedreturnfailure
Remark: In this pseudocode, if a node is reached by one path, removed from openSet, and subsequently reached by a cheaper path, it will be added to openSet again. This is essential to guarantee that the path returned is optimal if the heuristic function is admissible but not consistent. If the heuristic is consistent, when a node is removed from openSet the path to it is guaranteed to be optimal so the test ‘tentative_gScore < gScore[neighbor]’ will always fail if the node is reached again. The pseudocode implemented here is sometimes called the graph-search version of A*.[12] This is in contrast with the version without the ‘tentative_gScore < gScore[neighbor]’ test to add nodes back to openSet, which is sometimes called the tree-search version of A* and require a consistent heuristic to guarantee optimality.
Illustration of A* search for finding path from a start node to a goal node in a robotmotion planning problem. The empty circles represent the nodes in the open set, i.e., those that remain to be explored, and the filled ones are in the closed set. Color on each closed node indicates the distance from the goal: the greener, the closer. One can first see the A* moving in a straight line in the direction of the goal, then when hitting the obstacle, it explores alternative routes through the nodes from the open set.
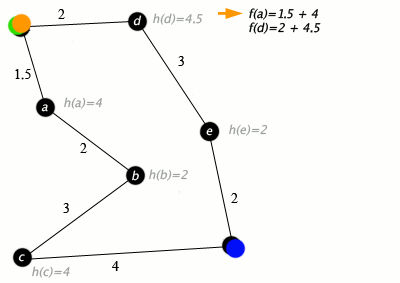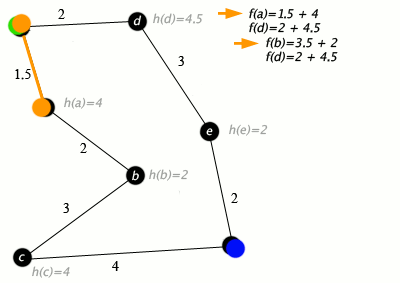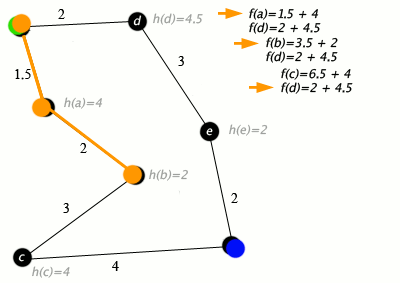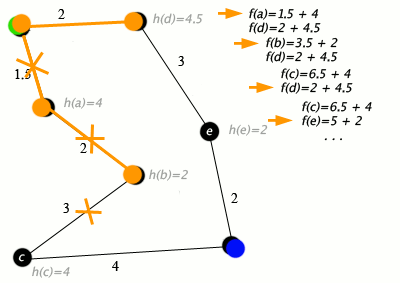
An example of an A* algorithm in action where nodes are cities connected with roads and h(x) is the straight-line distance to the target point:
Key: green: start; blue: goal; orange: visited
The A* algorithm has real-world applications. In this example, edges are railroads and h(x) is the great-circle distance (the shortest possible distance on a sphere) to the target. The algorithm is searching for a path between Washington, D.C., and Los Angeles.
Implementation details
There are a number of simple optimizations or implementation details that can significantly affect the performance of an A* implementation. The first detail to note is that the way the priority queue handles ties can have a significant effect on performance in some situations. If ties are broken so the queue behaves in a LIFO manner, A* will behave like depth-first search among equal cost paths (avoiding exploring more than one equally optimal solution).
When a path is required at the end of the search, it is common to keep with each node a reference to that node's parent. At the end of the search, these references can be used to recover the optimal path. If these references are being kept then it can be important that the same node doesn't appear in the priority queue more than once (each entry corresponding to a different path to the node, and each with a different cost). A standard approach here is to check if a node about to be added already appears in the priority queue. If it does, then the priority and parent pointers are changed to correspond to the lower-cost path. A standard binary heap based priority queue does not directly support the operation of searching for one of its elements, but it can be augmented with a hash table that maps elements to their position in the heap, allowing this decrease-priority operation to be performed in logarithmic time. Alternatively, a Fibonacci heap can perform the same decrease-priority operations in constant amortized time.
Special cases
Dijkstra's algorithm, as another example of a uniform-cost search algorithm, can be viewed as a special case of A* where for all x.[13][14] General depth-first search can be implemented using A* by considering that there is a global counter C initialized with a very large value. Every time we process a node we assign C to all of its newly discovered neighbors. After every single assignment, we decrease the counter C by one. Thus the earlier a node is discovered, the higher its value. Both Dijkstra's algorithm and depth-first search can be implemented more efficiently without including an value at each node.
Properties
Termination and completeness
On finite graphs with non-negative edge weights A* is guaranteed to terminate and is complete, i.e. it will always find a solution (a path from start to goal) if one exists. On infinite graphs with a finite branching factor and edge costs that are bounded away from zero ( for some fixed ), A* is guaranteed to terminate only if there exists a solution.[1]
Admissibility
A search algorithm is said to be admissible if it is guaranteed to return an optimal solution. If the heuristic function used by A* is admissible, then A* is admissible. An intuitive "proof" of this is as follows:
Call a node closed if it has been visited and is not in the open set. We close a node when we remove it from the open set. A basic property of the A* algorithm, which we'll sketch a proof of below, is that when is closed, is an optimistic estimate (lower bound) of the true distance from the start to the goal. So when the goal node, , is closed, is no more than the true distance. On the other hand, it is no less than the true distance, since it is the length of a path to the goal plus a heuristic term.
Now we'll see that whenever a node is closed, is an optimistic estimate. It is enough to see that whenever the open set is not empty, it has at least one node on an optimal path to the goal for which is the true distance from start, since in that case + underestimates the distance to goal, and therefore so does the smaller value chosen for the closed vertex. Let be an optimal path from the start to the goal. Let be the last closed node on for which is the true distance from the start to (the start is one such vertex). The next node in has the correct value, since it was updated when was closed, and it is open since it is not closed.
Optimality and consistency
Algorithm A is optimally efficient with respect to a set of alternative algorithms Alts on a set of problems P if for every problem P in P and every algorithm A′ in Alts, the set of nodes expanded by A in solving P is a subset (possibly equal) of the set of nodes expanded by A′ in solving P. The definitive study of the optimal efficiency of A* is due to Rina Dechter and Judea Pearl.[10] They considered a variety of definitions of Alts and P in combination with A*'s heuristic being merely admissible or being both consistent and admissible. The most interesting positive result they proved is that A*, with a consistent heuristic, is optimally efficient with respect to all admissible A*-like search algorithms on all "non-pathological" search problems. Roughly speaking, their notion of the non-pathological problem is what we now mean by "up to tie-breaking". This result does not hold if A*'s heuristic is admissible but not consistent. In that case, Dechter and Pearl showed there exist admissible A*-like algorithms that can expand arbitrarily fewer nodes than A* on some non-pathological problems.
Optimal efficiency is about the set of nodes expanded, not the number of node expansions (the number of iterations of A*'s main loop). When the heuristic being used is admissible but not consistent, it is possible for a node to be expanded by A* many times, an exponential number of times in the worst case.[15] In such circumstances, Dijkstra's algorithm could outperform A* by a large margin. However, more recent research found that this pathological case only occurs in certain contrived situations where the edge weight of the search graph is exponential in the size of the graph and that certain inconsistent (but admissible) heuristics can lead to a reduced number of node expansions in A* searches.[16][17]
Bounded relaxation
A* search that uses a heuristic that is 5.0(=ε) times a consistent heuristic, and obtains a suboptimal path
While the admissibility criterion guarantees an optimal solution path, it also means that A* must examine all equally meritorious paths to find the optimal path. To compute approximate shortest paths, it is possible to speed up the search at the expense of optimality by relaxing the admissibility criterion. Oftentimes we want to bound this relaxation, so that we can guarantee that the solution path is no worse than (1 + ε) times the optimal solution path. This new guarantee is referred to as ε-admissible.
There are a number of ε-admissible algorithms:
Weighted A*/Static Weighting's.[18] If ha(n) is an admissible heuristic function, in the weighted version of the A* search one uses hw(n) = ε ha(n), ε > 1 as the heuristic function, and perform the A* search as usual (which eventually happens faster than using ha since fewer nodes are expanded). The path hence found by the search algorithm can have a cost of at most ε times that of the least cost path in the graph.[19]
Convex Upward/Downward Parabola (XUP/XDP).[20] Modification to the cost function in weighted A* to push optimality toward the start or goal. XDP gives paths which are near optimal close to the start, and XUP paths are near-optimal close to the goal. Both yield -optimal paths overall.
.
.
Piecewise Upward/Downward Curve (pwXU/pwXD).[21] Similar to XUP/XDP but with piecewise functions instead of parabola. Solution paths are also -optimal.
Dynamic Weighting[22] uses the cost function , where , and where is the depth of the search and N is the anticipated length of the solution path.
Sampled Dynamic Weighting[23] uses sampling of nodes to better estimate and debias the heuristic error.
.[24] uses two heuristic functions. The first is the FOCAL list, which is used to select candidate nodes, and the second hF is used to select the most promising node from the FOCAL list.
Aε[25] selects nodes with the function , where A and B are constants. If no nodes can be selected, the algorithm will backtrack with the function , where C and D are constants.
AlphA*[26] attempts to promote depth-first exploitation by preferring recently expanded nodes. AlphA* uses the cost function , where , where λ and Λ are constants with , π(n) is the parent of n, and ñ is the most recently expanded node.
Complexity
As a heuristic search algorithm, the performance of A* is heavily influenced by the quality of the heuristic function . If the heuristic closely approximates the true cost to the goal, A* can significantly reduce the number of node expansions. On the other hand, a poor heuristic can lead to many unnecessary expansions.
Worst case
In the worst case, A* expands all nodes for which , where is the cost of the optimal goal node.
Why it cannot be worse
Suppose there is a node in the open list with , and it's the next node to be expanded. Since the goal node has , and , the goal node will have a lower f-value and will be expanded before . Therefore, A* never expands nodes with .
Why it cannot be better
Assume there exists an optimal algorithm that expands fewer nodes than in the worst case using the same heuristic. That means there must be some node such that , yet the algorithm chooses not to expand it.
Now consider a modified graph where a new edge of cost (with ) is added from to the goal. If , then the new optimal path goes through . However, since the algorithm still avoids expanding , it will miss the new optimal path, violating its optimality.
Therefore, no optimal algorithm including A* could expand fewer nodes than in the worst case.
Mathematical notation
The worst-case complexity of A* is often described as , where is the branching factor and is the depth of the shallowest goal. While this gives a rough intuition, it does not precisely capture the actual behavior of A*.
A more accurate bound considers the number of nodes with . If is the smallest possible difference in -cost between distinct nodes, then A* may expand up to:
This represents both the time and space complexity in the worst case.
Space complexity
The space complexity of A* is roughly the same as that of all other graph search algorithms, as it keeps all generated nodes in memory.[1] In practice, this turns out to be the biggest drawback of the A* search, leading to the development of memory-bounded heuristic searches, such as Iterative deepening A*, memory-bounded A*, and SMA*.
Applications
A* is often used for the common pathfinding problem in applications such as video games, but was originally designed as a general graph traversal algorithm.[4] It finds applications in diverse problems, including the problem of parsing using stochastic grammars in NLP.[27] Other cases include an Informational search with online learning.[28]
Relations to other algorithms
What sets A* apart from a greedy best-first search algorithm is that it takes the cost/distance already traveled, g(n), into account.
↑"A*-like" means the algorithm searches by extending paths originating at the start node one edge at a time, just as A* does. This excludes, for example, algorithms that search backward from the goal or in both directions simultaneously. In addition, the algorithms covered by this theorem must be admissible, and "not more informed" than A*.
↑Goal nodes may be passed over multiple times if there remain other nodes with lower f values, as they may lead to a shorter path to a goal.
↑Nilsson, Nils J. (2009-10-30). The Quest for Artificial Intelligence(PDF). Cambridge: Cambridge University Press. ISBN9780521122931. One of the first problems we considered was how to plan a sequence of 'way points' that Shakey could use in navigating from place to place. […] Shakey's navigation problem is a search problem, similar to ones I have mentioned earlier.
↑Nilsson, Nils J. (2009-10-30). The Quest for Artificial Intelligence(PDF). Cambridge: Cambridge University Press. ISBN9780521122931. Bertram Raphael, who was directing work on Shakey at that time, observed that a better value for the score would be the sum of the distance traveled so far from the initial position plus my heuristic estimate of how far the robot had to go.
↑Pohl, Ira (1970). "First results on the effect of error in heuristic search". Machine Intelligence 5. Edinburgh University Press: 219–236. ISBN978-0-85224-176-9. OCLC1067280266.
↑Chen, Jingwei; Sturtevant, Nathan R. (2019). "Conditions for Avoiding Node Re-expansions in Bounded Suboptimal Search". Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization: 1220–1226.
↑Ferguson, Dave; Likhachev, Maxim; Stentz, Anthony (2005). "A Guide to Heuristic-based Path Planning"(PDF). Proceedings of the international workshop on planning under uncertainty for autonomous systems, international conference on automated planning and scheduling (ICAPS). pp.9–18. Archived(PDF) from the original on 2016-06-29.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.