Related Research Articles
ISO/IEC 8859-3:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 3: Latin alphabet No. 3, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1988. It is informally referred to as Latin-3 or South European. It was designed to cover Turkish, Maltese and Esperanto, though the introduction of ISO/IEC 8859-9 superseded it for Turkish. The encoding was popular for users of Esperanto, but fell out of use as application support for Unicode became more common.
Windows-1258 is a code page used in Microsoft Windows to represent Vietnamese texts. It makes use of combining diacritical marks.

Code page 855 is a code page used under DOS to write Cyrillic script.
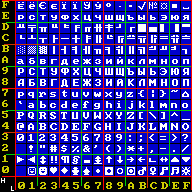
Code page 866 is a code page used under DOS and OS/2 in Russia to write Cyrillic script. It is based on the "alternative code page" developed in 1984 in IHNA AS USSR and published in 1986 by a research group at the Academy of Science of the USSR. The code page was widely used during the DOS era because it preserves all of the pseudographic symbols of code page 437 and maintains alphabetic order of Cyrillic letters. Initially this encoding was only available in the Russian version of MS-DOS 4.01 (1990), but with MS-DOS 6.22 it became available in any language version.
Code page 860 is a code page used under DOS in Portugal to write Portuguese and it is also suitable to write Spanish and Italian. In Brazil, however, the most widespread codepage – and that which DOS in Brazilian Portuguese used by default – was code page 850.
Code page 864 is a code page used to write Arabic in Egypt, Iraq, Jordan, Saudi Arabia, and Syria.
Code page 856, is a code page used under DOS for Hebrew in Israel.
Code page 1009, also known as CP1009 (IBM) and CP20105 (Microsoft), is the International Reference Version (IRV) of ISO 646:1983 until its redefinition in ISO/IEC 646:1991.
Code page 1014, also known as CP1014, is IBM's code page for the Spanish version of ISO 646 for Spain.
Code page 1018, also known as CP1018, is IBM's code page for the Swedish and Finnish version of ISO 646, specified in SFS 4017 and SEN 850200 Annex B, SIS 63 61 27.
Code page 1107, also known as CP1107, is an IBM code page number assigned to the alternate Denmark/Norway variant of DEC's National Replacement Character Set (NRCS). The 7-bit character set was introduced for DEC's computer terminal systems, starting with the VT200 series in 1983, but is also used by IBM for their DEC emulation. Similar but not identical to the series of ISO 646 character sets, the character set is a close derivation from ASCII with only six code points differing.
Code page 896, called Japan 7-Bit Katakana Extended, is IBM's code page for code-set G2 of EUC-JP, a 7-bit code page representing the Kana set of JIS X 0201 and accompanying Code page 895 which corresponds to the lower half of that standard. It encodes half-width katakana.
Code page 921 is a code page used under IBM AIX and DOS to write the Estonian, Latvian, and Lithuanian languages. It is an extension of ISO/IEC 8859-13. The original code page matched ISO/IEC 8859-13 directly.
Code page 922 is a code page used under IBM AIX and DOS to write the Estonian language. It is an extension and modification of ISO/IEC 8859-1, where the letters Ð/ð and Þ/þ used for Icelandic are replaced by the letters Š/š and Ž/ž respectively. This matches the encoding of these letters in Windows-1257 and ISO/IEC 8859-13.
Code page 904 is encoded for use as the single byte component of certain traditional Chinese character encodings. It is used in Taiwan. When combined with the double-byte Code page 927, it forms the two code-sets of Code page 938.
Code page 1006, also known as ISO 8-bit Urdu, is used by IBM in its AIX operating system in Pakistan for Urdu.
Code page 1008, also known as ISO 8-bit Arabic, is used by IBM in its AIX operating system.
Code page 1043, also known as Traditional Chinese PC Data Extended, is a single byte character set (SBCS) used by IBM in its PC DOS operating system. This code page is intended for use with code page 927. It is an extension of Code page 904.
Code page 1046, also known as Arabic Extended-Euro, is used by IBM platforms in Egypt, Iraq, Jordan, Saudi Arabia, and Syria for Arabic. It is similar to the DOS code page 1127.
Code page 1115, also known as Simplified Chinese PC Data, is a single byte character set (SBCS) used by IBM in its PC DOS operating system in China.
References
- ↑ "CCSID 853 information document". Archived from the original on 2016-03-27.
- ↑ Code Page CPGID 00853 (pdf) (PDF), IBM
- ↑ Code Page CPGID 00853 (txt), IBM
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |