Related Research Articles

Mojibake is the garbled or gibberish text that is the result of text being decoded using an unintended character encoding. The result is a systematic replacement of symbols with completely unrelated ones, often from a different writing system.
In computing, a code page is a character encoding and as such it is a specific association of a set of printable characters and control characters with unique numbers. Typically each number represents the binary value in a single byte.
The yen and yuan sign (¥) is a currency sign used for the Japanese yen and the Chinese yuan currencies when writing in Latin scripts. This character resembles a capital letter Y with a single or double horizontal stroke. The symbol is usually placed before the value it represents, for example: ¥50, or JP¥50 and CN¥50 when disambiguation is needed. When writing in Japanese and Chinese, the Japanese kanji and Chinese character is written following the amount, for example 50円 in Japan, and 50元 or 50圆 in China.

In typography, a dingbat is an ornament, specifically, a glyph used in typesetting, often employed to create box frames, or as a dinkus. Some of the dingbat symbols have been used as signature marks or used in bookbinding to order sections.
4DOS is a command-line interpreter by JP Software, designed to replace the default command interpreter COMMAND.COM in Microsoft DOS and Windows. It was written by Rex C. Conn and Tom Rawson and first released in 1989. Compared to the default, it has a large number of enhancements.

ArmSCII or ARMSCII is a set of obsolete single-byte character encodings for the Armenian alphabet defined by Armenian national standard 166–9. ArmSCII is an acronym for Armenian Standard Code for Information Interchange, similar to ASCII for the American standard. It has been superseded by the Unicode standard.

Code page 850 is a code page used under DOS operating systems in Western Europe. Depending on the country setting and system configuration, code page 850 is the primary code page and default OEM code page in many countries, including various English-speaking locales, whilst other English-speaking locales default to the hardware code page 437.

Code page 437 is the character set of the original IBM PC. It is also known as CP437, OEM-US, OEM 437, PC-8, or DOS Latin US. The set includes all printable ASCII characters as well as some accented letters (diacritics), Greek letters, icons, and line-drawing symbols. It is sometimes referred to as the "OEM font" or "high ASCII", or as "extended ASCII".
The Kamenický encoding, named for the brothers Jiří and Marian Kamenický, was a code page for personal computers running DOS, very popular in Czechoslovakia around 1985–1995. Another name for this encoding is KEYBCS2, the name of the terminate-and-stay-resident utility which implemented the matching keyboard driver. It was also named KAMENICKY.
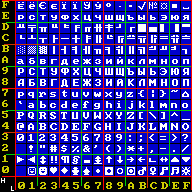
Code page 866 is a code page used under DOS and OS/2 in Russia to write Cyrillic script. It is based on the "alternative code page" developed in 1984 in IHNA AS USSR and published in 1986 by a research group at the Academy of Science of the USSR. The code page was widely used during the DOS era because it preserves all of the pseudographic symbols of code page 437 and maintains alphabetic order of Cyrillic letters. Initially this encoding was only available in the Russian version of MS-DOS 4.01 (1990), but with MS-DOS 6.22 it became available in any language version.
Code page 852 is a code page used under DOS to write Central European languages that use Latin script.
Several 8-bit character sets (encodings) were designed for binary representation of common Western European languages, which use the Latin alphabet, a few additional letters and ones with precomposed diacritics, some punctuation, and various symbols. These character sets also happen to support many other languages such as Malay, Swahili, and Classical Latin.
Personal Printer Data Stream is a general name for a family of page description language used by IBM printers, which includes all Proprinter, Quietwriter, Quickwriter, LaserPrinter 4019, and LaserPrinter 4029 commands.
ESC/P, short for Epson Standard Code for Printers and sometimes styled Escape/P, is a printer control language developed by Epson to control computer printers. It was mainly used in dot matrix printers and some inkjet printers, and is still widely used in many receipt thermal printers. During the era of dot matrix printers, it was also used by other manufacturers, sometimes in modified form. At the time, it was a popular mechanism to add formatting to printed text, and was widely supported in software.
In computing, a hardware code page (HWCP) refers to a code page supported natively by a hardware device such as a display adapter or printer. The glyphs to present the characters are stored in the alphanumeric character generator's resident read-only memory and are thus not user-changeable. They are available for use by the system without having to load any font definitions into the device first. Startup messages issued by a PC's System BIOS or displayed by an operating system before initializing its own code page switching logic and font management and before switching to graphics mode are displayed in a computer's default hardware code page.
CWI-2 is a Hungarian code page frequently used in the 1980s and early 1990s. If this code page is erroneously interpreted as code page 437, it will still be fairly readable.

The Atari ST character set is the character set of the Atari ST personal computer family including the Atari STE, TT and Falcon. It is based on code page 437, the original character set of the IBM PC.
The GEM character set is the character set of Digital Research's graphical user interface GEM on Intel platforms. It is based on code page 437, the original character set of the IBM PC.
Mac OS Sámi is a character encoding used on classic Mac OS to represent the Sámi languages and the Finnish Kalo language. While not used in any official Apple product, it has been used in various fonts designed to support Sámi languages under classic Mac OS, including those from Evertype. FreeDOS calls it code page 58630.
References
- 1 2 Paul, Matthias R. (2001) [1996]. "Specification and reference documentation for NECPINW". NECPINW.CPI - DOS code page switching driver for NEC Pinwriters (2.08 ed.). FILESPEC.TXT from NECPI208.ZIP. Archived from the original on 2017-09-10. Retrieved 2013-04-22.
- ↑ Fujitsu DL6400/DL6600 Dot Matrix Printer User's Manual (PDF). Fujitsu Limited. April 1994. C147-E015-01EN. Archived (PDF) from the original on 2016-06-14. Retrieved 2016-06-14.
- ↑ Pinwriter Familie - Pinwriter - Epromsockel - Zusätzliche Zeichensätze / Schriftarten (Printed reference manual for optional font and codepage EPROMs for NEC Pinwriters, including custom variants) (in German) (00 3/93 ed.). NEC Deutschland GmbH. 1993. (NB. Some dot matrix printers of the NEC Pinwriter series, namely the P3200/P3300 (P20/P30), P6200/P6300 (P60/P70), P9300 (P90), P7200/P7300 (P62/P72), P22Q/P32Q, P3800/P3900 (P42Q/P52Q), P1200/P1300 (P2Q/P3Q), P2000 (P2X) and P8000 (P72X), supported the installation of optional font EPROMs, where this encoding was included in ROM #8 "Polish". It could be invoked via escape sequence
ESC R (n)with (n) = 21.)
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |