
In genetics, a promoter is a sequence of DNA to which proteins bind to initiate transcription of a single RNA transcript from the DNA downstream of the promoter. The RNA transcript may encode a protein (mRNA), or can have a function in and of itself, such as tRNA or rRNA. Promoters are located near the transcription start sites of genes, upstream on the DNA . Promoters can be about 100–1000 base pairs long, the sequence of which is highly dependent on the gene and product of transcription, type or class of RNA polymerase recruited to the site, and species of organism.

Transcription is the process of copying a segment of DNA into RNA. The segments of DNA transcribed into RNA molecules that can encode proteins are said to produce messenger RNA (mRNA). Other segments of DNA are copied into RNA molecules called non-coding RNAs (ncRNAs). mRNA comprises only 1–3% of total RNA samples. Less than 2% of the human genome can be transcribed into mRNA, while at least 80% of mammalian genomic DNA can be actively transcribed, with the majority of this 80% considered to be ncRNA.
A regulatory sequence is a segment of a nucleic acid molecule which is capable of increasing or decreasing the expression of specific genes within an organism. Regulation of gene expression is an essential feature of all living organisms and viruses.
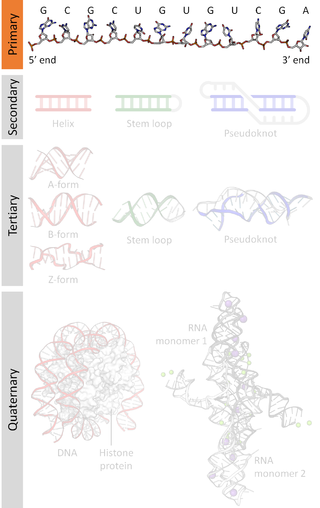
A nucleic acid sequence is a succession of bases signified by a series of a set of five different letters that indicate the order of nucleotides forming alleles within a DNA or RNA (GACU) molecule. By convention, sequences are usually presented from the 5' end to the 3' end. For DNA, the sense strand is used. Because nucleic acids are normally linear (unbranched) polymers, specifying the sequence is equivalent to defining the covalent structure of the entire molecule. For this reason, the nucleic acid sequence is also termed the primary structure.
In molecular biology and genetics, transcriptional regulation is the means by which a cell regulates the conversion of DNA to RNA (transcription), thereby orchestrating gene activity. A single gene can be regulated in a range of ways, from altering the number of copies of RNA that are transcribed, to the temporal control of when the gene is transcribed. This control allows the cell or organism to respond to a variety of intra- and extracellular signals and thus mount a response. Some examples of this include producing the mRNA that encode enzymes to adapt to a change in a food source, producing the gene products involved in cell cycle specific activities, and producing the gene products responsible for cellular differentiation in multicellular eukaryotes, as studied in evolutionary developmental biology.
In biology, a sequence motif is a nucleotide or amino-acid sequence pattern that is widespread and usually assumed to be related to biological function of the macromolecule. For example, an N-glycosylation site motif can be defined as Asn, followed by anything but Pro, followed by either Ser or Thr, followed by anything but Pro residue.
In molecular biology, the TATA box is a sequence of DNA found in the core promoter region of genes in archaea and eukaryotes. The bacterial homolog of the TATA box is called the Pribnow box which has a shorter consensus sequence.

In bioinformatics, a sequence logo is a graphical representation of the sequence conservation of nucleotides or amino acids . A sequence logo is created from a collection of aligned sequences and depicts the consensus sequence and diversity of the sequences. Sequence logos are frequently used to depict sequence characteristics such as protein-binding sites in DNA or functional units in proteins.

A primary transcript is the single-stranded ribonucleic acid (RNA) product synthesized by transcription of DNA, and processed to yield various mature RNA products such as mRNAs, tRNAs, and rRNAs. The primary transcripts designated to be mRNAs are modified in preparation for translation. For example, a precursor mRNA (pre-mRNA) is a type of primary transcript that becomes a messenger RNA (mRNA) after processing.
This is a list of topics in molecular biology. See also index of biochemistry articles.
In molecular biology, a CCAAT box is a distinct pattern of nucleotides with GGCCAATCT consensus sequence that occur upstream by 60–100 bases to the initial transcription site. The CAAT box signals the binding site for the RNA transcription factor, and is typically accompanied by a conserved consensus sequence. It is an invariant DNA sequence at about minus 70 base pairs from the origin of transcription in many eukaryotic promoters. Genes that have this element seem to require it for the gene to be transcribed in sufficient quantities. It is frequently absent from genes that encode proteins used in virtually all cells. This box along with the GC box is known for binding general transcription factors. Both of these consensus sequences belong to the regulatory promoter. Full gene expression occurs when transcription activator proteins bind to each module within the regulatory promoter. Protein specific binding is required for the CCAAT box activation. These proteins are known as CCAAT box binding proteins/CCAAT box binding factors.
Cis-regulatory elements (CREs) or Cis-regulatory modules (CRMs) are regions of non-coding DNA which regulate the transcription of neighboring genes. CREs are vital components of genetic regulatory networks, which in turn control morphogenesis, the development of anatomy, and other aspects of embryonic development, studied in evolutionary developmental biology.
Antitermination is the prokaryotic cell's aid to fix premature termination of RNA synthesis during the transcription of RNA. It occurs when the RNA polymerase ignores the termination signal and continues elongating its transcript until a second signal is reached. Antitermination provides a mechanism whereby one or more genes at the end of an operon can be switched either on or off, depending on the polymerase either recognizing or not recognizing the termination signal.
Bacterial transcription is the process in which a segment of bacterial DNA is copied into a newly synthesized strand of messenger RNA (mRNA) with use of the enzyme RNA polymerase.
Eukaryotic transcription is the elaborate process that eukaryotic cells use to copy genetic information stored in DNA into units of transportable complementary RNA replica. Gene transcription occurs in both eukaryotic and prokaryotic cells. Unlike prokaryotic RNA polymerase that initiates the transcription of all different types of RNA, RNA polymerase in eukaryotes comes in three variations, each translating a different type of gene. A eukaryotic cell has a nucleus that separates the processes of transcription and translation. Eukaryotic transcription occurs within the nucleus where DNA is packaged into nucleosomes and higher order chromatin structures. The complexity of the eukaryotic genome necessitates a great variety and complexity of gene expression control.
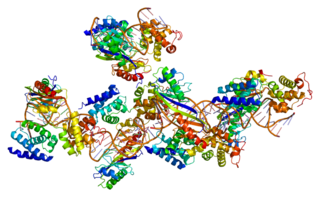
Transcription factor II B (TFIIB) is a general transcription factor that is involved in the formation of the RNA polymerase II preinitiation complex (PIC) and aids in stimulating transcription initiation. TFIIB is localised to the nucleus and provides a platform for PIC formation by binding and stabilising the DNA-TBP complex and by recruiting RNA polymerase II and other transcription factors. It is encoded by the TFIIB gene, and is homologous to archaeal transcription factor B and analogous to bacterial sigma factors.

The initiator element (Inr), sometimes referred to as initiator motif, is a core promoter that is similar in function to the Pribnow box or the TATA box. The Inr is the simplest functional promoter that is able to direct transcription initiation without a functional TATA box. It has the consensus sequence YYANWYY in humans. Similarly to the TATA box, the Inr element facilitates the binding of transcription Factor II D (TFIID). The Inr works by enhancing binding affinity and strengthening the promoter.
RNA polymerase II holoenzyme is a form of eukaryotic RNA polymerase II that is recruited to the promoters of protein-coding genes in living cells. It consists of RNA polymerase II, a subset of general transcription factors, and regulatory proteins known as SRB proteins.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology, cell biology, and evolutionary biology. It is intended as introductory material for novices; for more specific and technical detail, see the article corresponding to each term. For related terms, see Glossary of evolutionary biology.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology, cell biology, and evolutionary biology. It is split across two articles: