Apache Lucene is a free and open-source search engine software library, originally written in Java by Doug Cutting. It is supported by the Apache Software Foundation and is released under the Apache Software License. Lucene is widely used as a standard foundation for production search applications.
A recommender system, or a recommendation system, is a subclass of information filtering system that provides suggestions for items that are most pertinent to a particular user. Recommender systems are particularly useful when an individual needs to choose an item from a potentially overwhelming number of items that a service may offer.
An annotation is extra information associated with a particular point in a document or other piece of information. It can be a note that includes a comment or explanation. Annotations are sometimes presented in the margin of book pages. For annotations of different digital media, see web annotation and text annotation.
A paraphrase or rephrase is the rendering of the same text in different words without losing the meaning of the text itself. More often than not, a paraphrased text can convey its meaning better than the original words. In other words, it is a copy of the text in meaning, but which is different from the original. For example, when someone tells a story they heard in their own words, they paraphrase, with the meaning being the same. The term itself is derived via Latin paraphrasis, from Ancient Greek παράφρασις (paráphrasis) 'additional manner of expression'. The act of paraphrasing is also called paraphrasis.
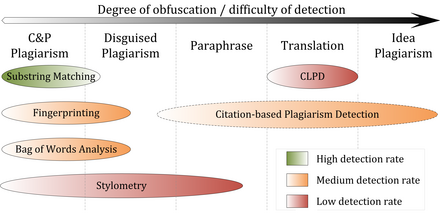
Citation analysis is the examination of the frequency, patterns, and graphs of citations in documents. It uses the directed graph of citations — links from one document to another document — to reveal properties of the documents. A typical aim would be to identify the most important documents in a collection. A classic example is that of the citations between academic articles and books. For another example, judges of law support their judgements by referring back to judgements made in earlier cases. An additional example is provided by patents which contain prior art, citation of earlier patents relevant to the current claim. The digitization of patent data and increasing computing power have led to a community of practice that uses these citation data to measure innovation attributes, trace knowledge flows, and map innovation networks.

Turnitin is an Internet-based similarity detection service run by the American company Turnitin, LLC, a subsidiary of Advance Publications.
Stylometry is the application of the study of linguistic style, usually to written language. It has also been applied successfully to music, paintings, and chess.
Bibliographic coupling, like co-citation, is a similarity measure that uses citation analysis to establish a similarity relationship between documents. Bibliographic coupling occurs when two works reference a common third work in their bibliographies. It is an indication that a probability exists that the two works treat a related subject matter.

JabRef is an open-source, cross-platform citation and reference management software. It is used to collect, organize and search bibliographic information.

In computer science, a fingerprinting algorithm is a procedure that maps an arbitrarily large data item to a much shorter bit string, its fingerprint, that uniquely identifies the original data for all practical purposes just as human fingerprints uniquely identify people for practical purposes. This fingerprint may be used for data deduplication purposes. This is also referred to as file fingerprinting, data fingerprinting, or structured data fingerprinting.

Plagiarism is the representation of another person's language, thoughts, ideas, or expressions as one's own original work. Although precise definitions vary depending on the institution, in many countries and cultures plagiarism is considered a violation of academic integrity and journalistic ethics, as well as social norms around learning, teaching, research, fairness, respect, and responsibility. As such, a person or entity that is determined to have committed plagiarism is often subject to various punishments or sanctions, such as suspension, expulsion from school or work, fines, imprisonment, and other penalties.
In computer programming and software development, debugging is the process of finding and resolving bugs within computer programs, software, or systems.
In statistics and natural language processing, a topic model is a type of statistical model for discovering the abstract "topics" that occur in a collection of documents. Topic modeling is a frequently used text-mining tool for discovery of hidden semantic structures in a text body. Intuitively, given that a document is about a particular topic, one would expect particular words to appear in the document more or less frequently: "dog" and "bone" will appear more often in documents about dogs, "cat" and "meow" will appear in documents about cats, and "the" and "is" will appear approximately equally in both. A document typically concerns multiple topics in different proportions; thus, in a document that is 10% about cats and 90% about dogs, there would probably be about 9 times more dog words than cat words. The "topics" produced by topic modeling techniques are clusters of similar words. A topic model captures this intuition in a mathematical framework, which allows examining a set of documents and discovering, based on the statistics of the words in each, what the topics might be and what each document's balance of topics is.
Co-citation is the frequency with which two documents are cited together by other documents. If at least one other document cites two documents in common, these documents are said to be co-cited. The more co-citations two documents receive, the higher their co-citation strength, and the more likely they are semantically related. Like bibliographic coupling, co-citation is a semantic similarity measure for documents that makes use of citation analyses.
In natural language processing and information retrieval, explicit semantic analysis (ESA) is a vectoral representation of text that uses a document corpus as a knowledge base. Specifically, in ESA, a word is represented as a column vector in the tf–idf matrix of the text corpus and a document is represented as the centroid of the vectors representing its words. Typically, the text corpus is English Wikipedia, though other corpora including the Open Directory Project have been used.

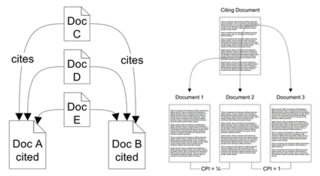
Co-citation Proximity Analysis (CPA) is a document similarity measure that uses citation analysis to assess semantic similarity between documents at both the global document level as well as at individual section-level. The similarity measure builds on the co-citation analysis approach, but differs in that it exploits the information implied in the placement of citations within the full-texts of documents.

In natural language processing, entity linking, also referred to as named-entity linking (NEL), named-entity disambiguation (NED), named-entity recognition and disambiguation (NERD) or named-entity normalization (NEN) is the task of assigning a unique identity to entities mentioned in text. For example, given the sentence "Paris is the capital of France", the idea is to determine that "Paris" refers to the city of Paris and not to Paris Hilton or any other entity that could be referred to as "Paris". Entity linking is different from named-entity recognition (NER) in that NER identifies the occurrence of a named entity in text but it does not identify which specific entity it is.
Paraphrase or paraphrasing in computational linguistics is the natural language processing task of detecting and generating paraphrases. Applications of paraphrasing are varied including information retrieval, question answering, text summarization, and plagiarism detection. Paraphrasing is also useful in the evaluation of machine translation, as well as semantic parsing and generation of new samples to expand existing corpora.
It is a common software engineering practice to develop software by using different components. Using software components segments the complexity of larger elements into smaller pieces of code and increases flexibility by enabling easier reuse of components to address new requirements. The practice has widely expanded since the late 1990s with the popularization of open-source software (OSS) to help speed up the software development process and reduce time to market.
Adversarial stylometry is the practice of altering writing style to reduce the potential for stylometry to discover the author's identity or their characteristics. This task is also known as authorship obfuscation or authorship anonymisation. Stylometry poses a significant privacy challenge in its ability to unmask anonymous authors or to link pseudonyms to an author's other identities, which, for example, creates difficulties for whistleblowers, activists, and hoaxers and fraudsters. The privacy risk is expected to grow as machine learning techniques and text corpora develop.