Texture mapping is a method for mapping a texture on a computer-generated graphic. Texture here can be high frequency detail, surface texture, or color.

A depth buffer, also known as a z-buffer, is a type of data buffer used in computer graphics to represent depth information of objects in 3D space from a particular perspective. The depth is stored as a height map of the scene, the values representing a distance to camera, with 0 being the closest. The encoding scheme may be flipped with the highest number being the value closest to camera. Depth buffers are an aid to rendering a scene to ensure that the correct polygons properly occlude other polygons. Z-buffering was first described in 1974 by Wolfgang Straßer in his PhD thesis on fast algorithms for rendering occluded objects. A similar solution to determining overlapping polygons is the painter's algorithm, which is capable of handling non-opaque scene elements, though at the cost of efficiency and incorrect results.

Ray casting is the methodological basis for 3D CAD/CAM solid modeling and image rendering. It is essentially the same as ray tracing for computer graphics where virtual light rays are "cast" or "traced" on their path from the focal point of a camera through each pixel in the camera sensor to determine what is visible along the ray in the 3D scene. The term "Ray Casting" was introduced by Scott Roth while at the General Motors Research Labs from 1978–1980. His paper, "Ray Casting for Modeling Solids", describes modeled solid objects by combining primitive solids, such as blocks and cylinders, using the set operators union (+), intersection (&), and difference (-). The general idea of using these binary operators for solid modeling is largely due to Voelcker and Requicha's geometric modelling group at the University of Rochester. See solid modeling for a broad overview of solid modeling methods. This figure on the right shows a U-Joint modeled from cylinders and blocks in a binary tree using Roth's ray casting system in 1979.
The scale-invariant feature transform (SIFT) is a computer vision algorithm to detect, describe, and match local features in images, invented by David Lowe in 1999. Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, individual identification of wildlife and match moving.

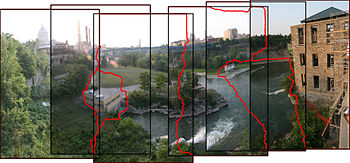
Hugin is a cross-platform open source panorama photo stitching and HDR merging program developed by Pablo d'Angelo and others. It is a GUI front-end for Helmut Dersch's Panorama Tools and Andrew Mihal's Enblend and Enfuse. Stitching is accomplished by using several overlapping photos taken from the same location, and using control points to align and transform the photos so that they can be blended together to form a larger image. Hugin allows for the easy creation of control points between two images, optimization of the image transforms along with a preview window so the user can see whether the panorama is acceptable. Once the preview is correct, the panorama can be fully stitched, transformed and saved in a standard image format.

In computer vision and image processing, motion estimation is the process of determining motion vectors that describe the transformation from one 2D image to another; usually from adjacent frames in a video sequence. It is an ill-posed problem as the motion happens in three dimensions (3D) but the images are a projection of the 3D scene onto a 2D plane. The motion vectors may relate to the whole image or specific parts, such as rectangular blocks, arbitrary shaped patches or even per pixel. The motion vectors may be represented by a translational model or many other models that can approximate the motion of a real video camera, such as rotation and translation in all three dimensions and zoom.
In geometric optics, distortion is a deviation from rectilinear projection; a projection in which straight lines in a scene remain straight in an image. It is a form of optical aberration.
Optical resolution describes the ability of an imaging system to resolve detail, in the object that is being imaged. An imaging system may have many individual components, including one or more lenses, and/or recording and display components. Each of these contributes to the optical resolution of the system; the environment in which the imaging is done often is a further important factor.
In the fields of computing and computer vision, pose represents the position and orientation of an object, usually in three dimensions. Poses are often stored internally as transformation matrices. The term “pose” is largely synonymous with the term “transform”, but a transform may often include scale, whereas pose does not.
Camera resectioning is the process of estimating the parameters of a pinhole camera model approximating the camera that produced a given photograph or video; it determines which incoming light ray is associated with each pixel on the resulting image. Basically, the process determines the pose of the pinhole camera.
The correspondence problem refers to the problem of ascertaining which parts of one image correspond to which parts of another image, where differences are due to movement of the camera, the elapse of time, and/or movement of objects in the photos.
Binocular disparity refers to the difference in image location of an object seen by the left and right eyes, resulting from the eyes’ horizontal separation (parallax). The mind uses binocular disparity to extract depth information from the two-dimensional retinal images in stereopsis. In computer vision, binocular disparity refers to the difference in coordinates of similar features within two stereo images.

Image rectification is a transformation process used to project images onto a common image plane. This process has several degrees of freedom and there are many strategies for transforming images to the common plane. Image rectification is used in computer stereo vision to simplify the problem of finding matching points between images, and in geographic information systems to merge images taken from multiple perspectives into a common map coordinate system.
In computer vision, triangulation refers to the process of determining a point in 3D space given its projections onto two, or more, images. In order to solve this problem it is necessary to know the parameters of the camera projection function from 3D to 2D for the cameras involved, in the simplest case represented by the camera matrices. Triangulation is sometimes also referred to as reconstruction or intersection.
In photogrammetry and computer stereo vision, bundle adjustment is simultaneous refining of the 3D coordinates describing the scene geometry, the parameters of the relative motion, and the optical characteristics of the camera(s) employed to acquire the images, given a set of images depicting a number of 3D points from different viewpoints. Its name refers to the geometrical bundles of light rays originating from each 3D feature and converging on each camera's optical center, which are adjusted optimally according to an optimality criterion involving the corresponding image projections of all points.

Image Composite Editor is an advanced panoramic image stitcher made by the Microsoft Research division of Microsoft Corporation.
Camera auto-calibration is the process of determining internal camera parameters directly from multiple uncalibrated images of unstructured scenes. In contrast to classic camera calibration, auto-calibration does not require any special calibration objects in the scene. In the visual effects industry, camera auto-calibration is often part of the "Match Moving" process where a synthetic camera trajectory and intrinsic projection model are solved to reproject synthetic content into video.

3D reconstruction from multiple images is the creation of three-dimensional models from a set of images. It is the reverse process of obtaining 2D images from 3D scenes.

In the field of computer vision, any two images of the same planar surface in space are related by a homography. This has many practical applications, such as image rectification, image registration, or camera motion—rotation and translation—between two images. Once camera resectioning has been done from an estimated homography matrix, this information may be used for navigation, or to insert models of 3D objects into an image or video, so that they are rendered with the correct perspective and appear to have been part of the original scene.
In computer vision, rigid motion segmentation is the process of separating regions, features, or trajectories from a video sequence into coherent subsets of space and time. These subsets correspond to independent rigidly moving objects in the scene. The goal of this segmentation is to differentiate and extract the meaningful rigid motion from the background and analyze it. Image segmentation techniques labels the pixels to be a part of pixels with certain characteristics at a particular time. Here, the pixels are segmented depending on its relative movement over a period of time i.e. the time of the video sequence.