Edge detection includes a variety of mathematical methods that aim at identifying edges, curves in a digital image at which the image brightness changes sharply or, more formally, has discontinuities. The same problem of finding discontinuities in one-dimensional signals is known as step detection and the problem of finding signal discontinuities over time is known as change detection. Edge detection is a fundamental tool in image processing, machine vision and computer vision, particularly in the areas of feature detection and feature extraction.

The Sobel operator, sometimes called the Sobel–Feldman operator or Sobel filter, is used in image processing and computer vision, particularly within edge detection algorithms where it creates an image emphasising edges. It is named after Irwin Sobel and Gary M. Feldman, colleagues at the Stanford Artificial Intelligence Laboratory (SAIL). Sobel and Feldman presented the idea of an "Isotropic 3 × 3 Image Gradient Operator" at a talk at SAIL in 1968. Technically, it is a discrete differentiation operator, computing an approximation of the gradient of the image intensity function. At each point in the image, the result of the Sobel–Feldman operator is either the corresponding gradient vector or the norm of this vector. The Sobel–Feldman operator is based on convolving the image with a small, separable, and integer-valued filter in the horizontal and vertical directions and is therefore relatively inexpensive in terms of computations. On the other hand, the gradient approximation that it produces is relatively crude, in particular for high-frequency variations in the image.

The Canny edge detector is an edge detection operator that uses a multi-stage algorithm to detect a wide range of edges in images. It was developed by John F. Canny in 1986. Canny also produced a computational theory of edge detection explaining why the technique works.
In mathematics, the discrete Laplace operator is an analog of the continuous Laplace operator, defined so that it has meaning on a graph or a discrete grid. For the case of a finite-dimensional graph, the discrete Laplace operator is more commonly called the Laplacian matrix.
Scale-space theory is a framework for multi-scale signal representation developed by the computer vision, image processing and signal processing communities with complementary motivations from physics and biological vision. It is a formal theory for handling image structures at different scales, by representing an image as a one-parameter family of smoothed images, the scale-space representation, parametrized by the size of the smoothing kernel used for suppressing fine-scale structures. The parameter in this family is referred to as the scale parameter, with the interpretation that image structures of spatial size smaller than about have largely been smoothed away in the scale-space level at scale .

In image processing, a Gaussian blur is the result of blurring an image by a Gaussian function.
The Prewitt operator is used in image processing, particularly within edge detection algorithms. Technically, it is a discrete differentiation operator, computing an approximation of the gradient of the image intensity function. At each point in the image, the result of the Prewitt operator is either the corresponding gradient vector or the norm of this vector. The Prewitt operator is based on convolving the image with a small, separable, and integer valued filter in horizontal and vertical directions and is therefore relatively inexpensive in terms of computations like Sobel and Kayyali operators. On the other hand, the gradient approximation which it produces is relatively crude, in particular for high frequency variations in the image. The Prewitt operator was developed by Judith M. S. Prewitt.

Geometry processing, or mesh processing, is an area of research that uses concepts from applied mathematics, computer science and engineering to design efficient algorithms for the acquisition, reconstruction, analysis, manipulation, simulation and transmission of complex 3D models. As the name implies, many of the concepts, data structures, and algorithms are directly analogous to signal processing and image processing. For example, where image smoothing might convolve an intensity signal with a blur kernel formed using the Laplace operator, geometric smoothing might be achieved by convolving a surface geometry with a blur kernel formed using the Laplace-Beltrami operator.
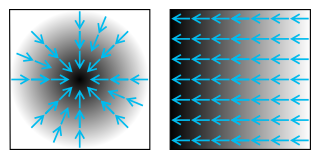
An image gradient is a directional change in the intensity or color in an image. The gradient of the image is one of the fundamental building blocks in image processing. For example, the Canny edge detector uses image gradient for edge detection. In graphics software for digital image editing, the term gradient or color gradient is also used for a gradual blend of color which can be considered as an even gradation from low to high values, as used from white to black in the images to the right. Another name for this is color progression.

Corner detection is an approach used within computer vision systems to extract certain kinds of features and infer the contents of an image. Corner detection is frequently used in motion detection, image registration, video tracking, image mosaicing, panorama stitching, 3D reconstruction and object recognition. Corner detection overlaps with the topic of interest point detection.
In image processing, ridge detection is the attempt, via software, to locate ridges in an image, defined as curves whose points are local maxima of the function, akin to geographical ridges.
In computer vision, blob detection methods are aimed at detecting regions in a digital image that differ in properties, such as brightness or color, compared to surrounding regions. Informally, a blob is a region of an image in which some properties are constant or approximately constant; all the points in a blob can be considered in some sense to be similar to each other. The most common method for blob detection is convolution.
Affine shape adaptation is a methodology for iteratively adapting the shape of the smoothing kernels in an affine group of smoothing kernels to the local image structure in neighbourhood region of a specific image point. Equivalently, affine shape adaptation can be accomplished by iteratively warping a local image patch with affine transformations while applying a rotationally symmetric filter to the warped image patches. Provided that this iterative process converges, the resulting fixed point will be affine invariant. In the area of computer vision, this idea has been used for defining affine invariant interest point operators as well as affine invariant texture analysis methods.
In mathematics, the structure tensor, also referred to as the second-moment matrix, is a matrix derived from the gradient of a function. It describes the distribution of the gradient in a specified neighborhood around a point and makes the information invariant respect the observing coordinates. The structure tensor is often used in image processing and computer vision.
In the fields of computer vision and image analysis, the Harris affine region detector belongs to the category of feature detection. Feature detection is a preprocessing step of several algorithms that rely on identifying characteristic points or interest points so to make correspondences between images, recognize textures, categorize objects or build panoramas.
In image processing and computer vision, anisotropic diffusion, also called Perona–Malik diffusion, is a technique aiming at reducing image noise without removing significant parts of the image content, typically edges, lines or other details that are important for the interpretation of the image. Anisotropic diffusion resembles the process that creates a scale space, where an image generates a parameterized family of successively more and more blurred images based on a diffusion process. Each of the resulting images in this family are given as a convolution between the image and a 2D isotropic Gaussian filter, where the width of the filter increases with the parameter. This diffusion process is a linear and space-invariant transformation of the original image. Anisotropic diffusion is a generalization of this diffusion process: it produces a family of parameterized images, but each resulting image is a combination between the original image and a filter that depends on the local content of the original image. As a consequence, anisotropic diffusion is a non-linear and space-variant transformation of the original image.
The Kirsch operator or Kirsch compass kernel is a non-linear edge detector that finds the maximum edge strength in a few predetermined directions. It is named after the computer scientist Russell Kirsch.
The principal curvature-based region detector, also called PCBR is a feature detector used in the fields of computer vision and image analysis. Specifically the PCBR detector is designed for object recognition applications.
In image processing, a kernel, convolution matrix, or mask is a small matrix used for blurring, sharpening, embossing, edge detection, and more. This is accomplished by doing a convolution between the kernel and an image. Or more simply, when each pixel in the output image is a function of the nearby pixels in the input image, the kernel is that function.

Gradient vector flow (GVF), a computer vision framework introduced by Chenyang Xu and Jerry L. Prince, is the vector field that is produced by a process that smooths and diffuses an input vector field. It is usually used to create a vector field from images that points to object edges from a distance. It is widely used in image analysis and computer vision applications for object tracking, shape recognition, segmentation, and edge detection. In particular, it is commonly used in conjunction with active contour model.












