Protein biosynthesis is a core biological process, occurring inside cells, balancing the loss of cellular proteins through the production of new proteins. Proteins perform a number of critical functions as enzymes, structural proteins or hormones. Protein synthesis is a very similar process for both prokaryotes and eukaryotes but there are some distinct differences.

Ribonucleic acid (RNA) is a polymeric molecule that is essential for most biological functions, either by performing the function itself or by forming a template for the production of proteins. RNA and deoxyribonucleic acid (DNA) are nucleic acids. The nucleic acids constitute one of the four major macromolecules essential for all known forms of life. RNA is assembled as a chain of nucleotides. Cellular organisms use messenger RNA (mRNA) to convey genetic information that directs synthesis of specific proteins. Many viruses encode their genetic information using an RNA genome.
An inverted repeat is a single stranded sequence of nucleotides followed downstream by its reverse complement. The intervening sequence of nucleotides between the initial sequence and the reverse complement can be any length including zero. For example, 5'---TTACGnnnnnnCGTAA---3' is an inverted repeat sequence. When the intervening length is zero, the composite sequence is a palindromic sequence.
In a chain-like biological molecule, such as a protein or nucleic acid, a structural motif is a common three-dimensional structure that appears in a variety of different, evolutionarily unrelated molecules. A structural motif does not have to be associated with a sequence motif; it can be represented by different and completely unrelated sequences in different proteins or RNA.

Biomolecular structure is the intricate folded, three-dimensional shape that is formed by a molecule of protein, DNA, or RNA, and that is important to its function. The structure of these molecules may be considered at any of several length scales ranging from the level of individual atoms to the relationships among entire protein subunits. This useful distinction among scales is often expressed as a decomposition of molecular structure into four levels: primary, secondary, tertiary, and quaternary. The scaffold for this multiscale organization of the molecule arises at the secondary level, where the fundamental structural elements are the molecule's various hydrogen bonds. This leads to several recognizable domains of protein structure and nucleic acid structure, including such secondary-structure features as alpha helixes and beta sheets for proteins, and hairpin loops, bulges, and internal loops for nucleic acids. The terms primary, secondary, tertiary, and quaternary structure were introduced by Kaj Ulrik Linderstrøm-Lang in his 1951 Lane Medical Lectures at Stanford University.

The hammerhead ribozyme is an RNA motif that catalyzes reversible cleavage and ligation reactions at a specific site within an RNA molecule. It is one of several catalytic RNAs (ribozymes) known to occur in nature. It serves as a model system for research on the structure and properties of RNA, and is used for targeted RNA cleavage experiments, some with proposed therapeutic applications. Named for the resemblance of early secondary structure diagrams to a hammerhead shark, hammerhead ribozymes were originally discovered in two classes of plant virus-like RNAs: satellite RNAs and viroids. They are also known in some classes of retrotransposons, including the retrozymes. The hammerhead ribozyme motif has been ubiquitously reported in lineages across the tree of life.

The hairpin ribozyme is a small section of RNA that can act as a ribozyme. Like the hammerhead ribozyme it is found in RNA satellites of plant viruses. It was first identified in the minus strand of the tobacco ringspot virus (TRSV) satellite RNA where it catalyzes self-cleavage and joining (ligation) reactions to process the products of rolling circle virus replication into linear and circular satellite RNA molecules. The hairpin ribozyme is similar to the hammerhead ribozyme in that it does not require a metal ion for the reaction.

A purine riboswitch is a sequence of ribonucleotides in certain messenger RNA (mRNA) that selectively binds to purine ligands via a natural aptamer domain. This binding causes a conformational change in the mRNA that can affect translation by revealing an expression platform for a downstream gene, or by forming a translation-terminating stem-loop. The ultimate effects of such translational regulation often take action to manage an abundance of the instigating purine, and might produce proteins that facilitate purine metabolism or purine membrane uptake.

The SAM riboswitch is found upstream of a number of genes which code for proteins involved in methionine or cysteine biosynthesis in Gram-positive bacteria. Two SAM riboswitches in Bacillus subtilis that were experimentally studied act at the level of transcription termination control. The predicted secondary structure consists of a complex stem-loop region followed by a single stem-loop terminator region. An alternative and mutually exclusive form involves bases in the 3' segment of helix 1 with those in the 5' region of helix 5 to form a structure termed the anti-terminator form. When SAM is unbound, the anti-terminator sequence sequesters the terminator sequence so the terminator is unable to form, allowing the polymerase to read-through the downstream gene. When S-Adenosyl methionine (SAM) is bound to the aptamer, the anti-terminator is sequestered by an anti-anti-terminator; the terminator forms and terminates the transcription. However, many SAM riboswitches are likely to regulate gene expression at the level of translation.

Intrinsic, or rho-independent termination, is a process to signal the end of transcription and release the newly constructed RNA molecule. In bacteria such as E. coli, transcription is terminated either by a rho-dependent process or rho-independent process. In the Rho-dependent process, the rho-protein locates and binds the signal sequence in the mRNA and signals for cleavage. Contrarily, intrinsic termination does not require a special protein to signal for termination and is controlled by the specific sequences of RNA. When the termination process begins, the transcribed mRNA forms a stable secondary structure hairpin loop, also known as a stem-loop. This RNA hairpin is followed by multiple uracil nucleotides. The bonds between uracil (rU) and adenine (dA) are very weak. A protein bound to RNA polymerase (nusA) binds to the stem-loop structure tightly enough to cause the polymerase to temporarily stall. This pausing of the polymerase coincides with transcription of the poly-uracil sequence. The weak adenine-uracil bonds lower the energy of destabilization for the RNA-DNA duplex, allowing it to unwind and dissociate from the RNA polymerase. Overall, the modified RNA structure is what terminates transcription.

Tetraloops are a type of four-base hairpin loop motifs in RNA secondary structure that cap many double helices. There are many variants of the tetraloop. The published ones include ANYA, CUYG, GNRA, UNAC and UNCG.

Red clover necrotic mosaic virus (RCNMV) contains several structural elements present within the 3′ and 5′ untranslated regions (UTR) of the genome that enhance translation. In eukaryotes transcription is a prerequisite for translation. During transcription the pre-mRNA transcript is processes where a 5′ cap is attached onto mRNA and this 5′ cap allows for ribosome assembly onto the mRNA as it acts as a binding site for the eukaryotic initiation factor eIF4F. Once eIF4F is bound to the mRNA this protein complex interacts with the poly(A) binding protein which is present within the 3′ UTR and results in mRNA circularization. This multiprotein-mRNA complex then recruits the ribosome subunits and scans the mRNA until it reaches the start codon. Transcription of viral genomes differs from eukaryotes as viral genomes produce mRNA transcripts that lack a 5’ cap site. Despite lacking a cap site viral genes contain a structural element within the 5’ UTR known as an internal ribosome entry site (IRES). IRES is a structural element that recruits the 40s ribosome subunit to the mRNA within close proximity of the start codon.
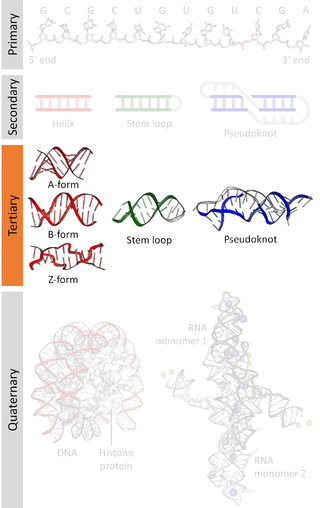
Nucleic acid tertiary structure is the three-dimensional shape of a nucleic acid polymer. RNA and DNA molecules are capable of diverse functions ranging from molecular recognition to catalysis. Such functions require a precise three-dimensional structure. While such structures are diverse and seemingly complex, they are composed of recurring, easily recognizable tertiary structural motifs that serve as molecular building blocks. Some of the most common motifs for RNA and DNA tertiary structure are described below, but this information is based on a limited number of solved structures. Many more tertiary structural motifs will be revealed as new RNA and DNA molecules are structurally characterized.
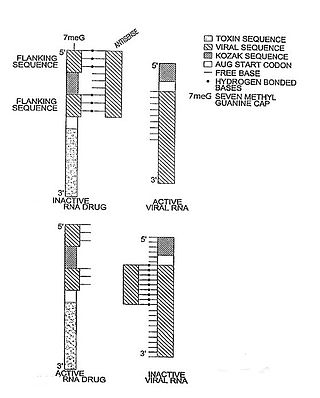
In molecular biology, a riboregulator is a ribonucleic acid (RNA) that responds to a signal nucleic acid molecule by Watson-Crick base pairing. A riboregulator may respond to a signal molecule in any number of manners including, translation of the RNA into a protein, activation of a ribozyme, release of silencing RNA (siRNA), conformational change, and/or binding other nucleic acids. Riboregulators contain two canonical domains, a sensor domain and an effector domain. These domains are also found on riboswitches, but unlike riboswitches, the sensor domain only binds complementary RNA or DNA strands as opposed to small molecules. Because binding is based on base-pairing, a riboregulator can be tailored to differentiate and respond to individual genetic sequences and combinations thereof.

Nucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary, and quaternary.

Nucleic acid secondary structure is the basepairing interactions within a single nucleic acid polymer or between two polymers. It can be represented as a list of bases which are paired in a nucleic acid molecule. The secondary structures of biological DNAs and RNAs tend to be different: biological DNA mostly exists as fully base paired double helices, while biological RNA is single stranded and often forms complex and intricate base-pairing interactions due to its increased ability to form hydrogen bonds stemming from the extra hydroxyl group in the ribose sugar.
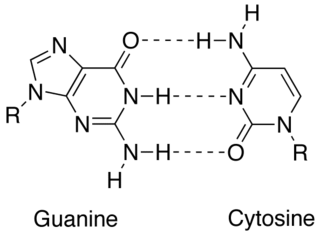
In molecular biology, complementarity describes a relationship between two structures each following the lock-and-key principle. In nature complementarity is the base principle of DNA replication and transcription as it is a property shared between two DNA or RNA sequences, such that when they are aligned antiparallel to each other, the nucleotide bases at each position in the sequences will be complementary, much like looking in the mirror and seeing the reverse of things. This complementary base pairing allows cells to copy information from one generation to another and even find and repair damage to the information stored in the sequences.

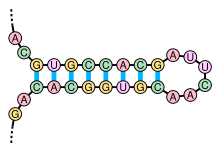
In genetics, a kissing stem-loop, or kissing stem loop interaction, is formed in ribonucleic acid (RNA) when two bases between two hairpin loops pair. These intra- and intermolecular kissing interactions are important in forming the tertiary or quaternary structure of many RNAs.
Non-canonical base pairs are planar hydrogen bonded pairs of nucleobases, having hydrogen bonding patterns which differ from the patterns observed in Watson-Crick base pairs, as in the classic double helical DNA. The structures of polynucleotide strands of both DNA and RNA molecules can be understood in terms of sugar-phosphate backbones consisting of phosphodiester-linked D 2’ deoxyribofuranose sugar moieties, with purine or pyrimidine nucleobases covalently linked to them. Here, the N9 atoms of the purines, guanine and adenine, and the N1 atoms of the pyrimidines, cytosine and thymine, respectively, form glycosidic linkages with the C1’ atom of the sugars. These nucleobases can be schematically represented as triangles with one of their vertices linked to the sugar, and the three sides accounting for three edges through which they can form hydrogen bonds with other moieties, including with other nucleobases. The side opposite to the sugar linked vertex is traditionally called the Watson-Crick edge, since they are involved in forming the Watson-Crick base pairs which constitute building blocks of double helical DNA. The two sides adjacent to the sugar-linked vertex are referred to, respectively, as the Sugar and Hoogsteen edges.
Coronavirus genomes are positive-sense single-stranded RNA molecules with an untranslated region (UTR) at the 3′ end which is called the 3′ UTR. The 3′ UTR is responsible for important biological functions, such as viral replication. The 3′ UTR has a conserved RNA secondary structure but different Coronavirus genera have different structural features described below.