Related Research Articles
Natural language processing (NLP) is an interdisciplinary subfield of computer science and information retrieval. It is primarily concerned with giving computers the ability to support and manipulate human language. It involves processing natural language datasets, such as text corpora or speech corpora, using either rule-based or probabilistic machine learning approaches. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. To this end, natural language processing often borrows ideas from theoretical linguistics. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
Word-sense disambiguation (WSD) is the process of identifying which sense of a word is meant in a sentence or other segment of context. In human language processing and cognition, it is usually subconscious/automatic but can often come to conscious attention when ambiguity impairs clarity of communication, given the pervasive polysemy in natural language. In computational linguistics, it is an open problem that affects other computer-related writing, such as discourse, improving relevance of search engines, anaphora resolution, coherence, and inference.
Text mining, text data mining (TDM) or text analytics is the process of deriving high-quality information from text. It involves "the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources." Written resources may include websites, books, emails, reviews, and articles. High-quality information is typically obtained by devising patterns and trends by means such as statistical pattern learning. According to Hotho et al. (2005) we can distinguish between three different perspectives of text mining: information extraction, data mining, and a knowledge discovery in databases (KDD) process. Text mining usually involves the process of structuring the input text, deriving patterns within the structured data, and finally evaluation and interpretation of the output. 'High quality' in text mining usually refers to some combination of relevance, novelty, and interest. Typical text mining tasks include text categorization, text clustering, concept/entity extraction, production of granular taxonomies, sentiment analysis, document summarization, and entity relation modeling.
An annotation is extra information associated with a particular point in a document or other piece of information. It can be a note that includes a comment or explanation. Annotations are sometimes presented in the margin of book pages. For annotations of different digital media, see web annotation and text annotation.
A paraphrase or rephrase is the rendering of the same text in different words without losing the meaning of the text itself. More often than not, a paraphrased text can convey its meaning better than the original words. In other words, it is a copy of the text in meaning, but which is different from the original. For example, when someone tells a story they heard in their own words, they paraphrase, with the meaning being the same. The term itself is derived via Latin paraphrasis, from Ancient Greek παράφρασις (paráphrasis) 'additional manner of expression'. The act of paraphrasing is also called paraphrasis.

Argumentation theory is the interdisciplinary study of how conclusions can be supported or undermined by premises through logical reasoning. With historical origins in logic, dialectic, and rhetoric, argumentation theory includes the arts and sciences of civil debate, dialogue, conversation, and persuasion. It studies rules of inference, logic, and procedural rules in both artificial and real-world settings.
Biomedical text mining refers to the methods and study of how text mining may be applied to texts and literature of the biomedical domain. As a field of research, biomedical text mining incorporates ideas from natural language processing, bioinformatics, medical informatics and computational linguistics. The strategies in this field have been applied to the biomedical literature available through services such as PubMed.
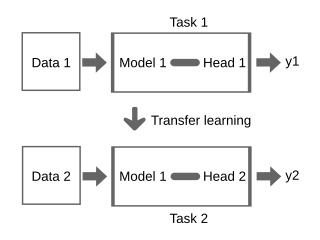
Transfer learning (TL) is a technique in machine learning (ML) in which knowledge learned from a task is re-used in order to boost performance on a related task. For example, for image classification, knowledge gained while learning to recognize cars could be applied when trying to recognize trucks. This topic is related to the psychological literature on transfer of learning, although practical ties between the two fields are limited. Reusing/transferring information from previously learned tasks to new tasks has the potential to significantly improve learning efficiency.
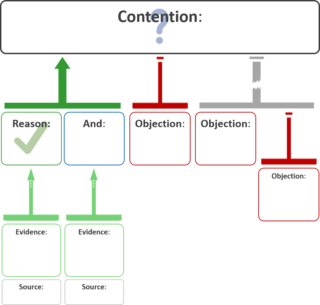
An argument map or argument diagram is a visual representation of the structure of an argument. An argument map typically includes all the key components of the argument, traditionally called the conclusion and the premises, also called contention and reasons. Argument maps can also show co-premises, objections, counterarguments, rebuttals, and lemmas. There are different styles of argument map but they are often functionally equivalent and represent an argument's individual claims and the relationships between them.
Sentiment analysis is the use of natural language processing, text analysis, computational linguistics, and biometrics to systematically identify, extract, quantify, and study affective states and subjective information. Sentiment analysis is widely applied to voice of the customer materials such as reviews and survey responses, online and social media, and healthcare materials for applications that range from marketing to customer service to clinical medicine. With the rise of deep language models, such as RoBERTa, also more difficult data domains can be analyzed, e.g., news texts where authors typically express their opinion/sentiment less explicitly.
An argument is a series of sentences, statements, or propositions some of which are called premises and one is the conclusion. The purpose of an argument is to give reasons for one's conclusion via justification, explanation, and/or persuasion.

In computer science, information science and systems engineering, ontology engineering is a field which studies the methods and methodologies for building ontologies, which encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities of a given domain of interest. In a broader sense, this field also includes a knowledge construction of the domain using formal ontology representations such as OWL/RDF. A large-scale representation of abstract concepts such as actions, time, physical objects and beliefs would be an example of ontological engineering. Ontology engineering is one of the areas of applied ontology, and can be seen as an application of philosophical ontology. Core ideas and objectives of ontology engineering are also central in conceptual modeling.
A discourse relation is a description of how two segments of discourse are logically and/or structurally connected to one another.
Inductive programming (IP) is a special area of automatic programming, covering research from artificial intelligence and programming, which addresses learning of typically declarative and often recursive programs from incomplete specifications, such as input/output examples or constraints.
Drama annotation is the process of annotating the metadata of a drama. Given a drama expressed in some medium, the process of metadata annotation identifies what are the elements that characterize the drama and annotates such elements in some metadata format. For example, in the sentence "Laertes and Polonius warn Ophelia to stay away from Hamlet." from the text Hamlet, the word "Laertes", which refers to a drama element, namely a character, will be annotated as "Char", taken from some set of metadata. This article addresses the drama annotation projects, with the sets of metadata and annotations proposed in the scientific literature, based markup languages and ontologies.
Argument technology is a sub-field of collective intelligence and artificial intelligence that focuses on applying computational techniques to the creation, identification, analysis, navigation, evaluation and visualisation of arguments and debates.
In argumentation theory, an argumentation scheme or argument scheme is a template that represents a common type of argument used in ordinary conversation. Many different argumentation schemes have been identified. Each one has a name and presents a type of connection between premises and a conclusion in an argument, and this connection is expressed as a rule of inference. Argumentation schemes can include inferences based on different types of reasoning—deductive, inductive, abductive, probabilistic, etc.
In network theory, link prediction is the problem of predicting the existence of a link between two entities in a network. Examples of link prediction include predicting friendship links among users in a social network, predicting co-authorship links in a citation network, and predicting interactions between genes and proteins in a biological network. Link prediction can also have a temporal aspect, where, given a snapshot of the set of links at time , the goal is to predict the links at time . Link prediction is widely applicable. In e-commerce, link prediction is often a subtask for recommending items to users. In the curation of citation databases, it can be used for record deduplication. In bioinformatics, it has been used to predict protein-protein interactions (PPI). It is also used to identify hidden groups of terrorists and criminals in security related applications.

Kialo is an online structured debate platform with argument maps in the form of debate trees. It is a collaborative reasoning tool for thoughtful discussion, understanding different points of view, and collaborative decision-making, showing arguments for and against claims underneath user-submitted theses or questions.
References
- 1 2 Lippi, Marco; Torroni, Paolo (2016-04-20). "Argumentation Mining: State of the Art and Emerging Trends". ACM Transactions on Internet Technology. 16 (2): 10. doi:10.1145/2850417. hdl: 11585/523460 . ISSN 1533-5399. S2CID 9561587.
- ↑ Budzynska, Katarzyna; Villata, Serena. "Argument Mining - IJCAI2016 Tutorial". www.i3s.unice.fr. Archived from the original on 2016-11-29. Retrieved 2018-03-30.
- ↑ Gurevych, Iryna; Reed, Chris; Slonim, Noam; Stein, Benno. "NLP Approaches to Computational Argumentation - ACL 2016 Tutorial".
- ↑ "5th Workshop on Argument Mining". 17 May 2011.
- ↑ Wambsganss, Thiemo; Molyndris, Nikolaos; Söllner, Matthias (2020-03-09), "Unlocking Transfer Learning in Argumentation Mining: A Domain-Independent Modelling Approach" (PDF), WI2020 Zentrale Tracks, GITO Verlag, pp. 341–356, doi: 10.30844/wi_2020_c9-wambsganss , ISBN 978-3-95545-335-0
- ↑ "AL: An Adaptive Learning Support System for Argumentation Skills | Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems" (PDF). doi:10.1145/3313831.3376732. S2CID 218482749.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Levy, Ran; Gretz, Shai; Sznajder, Benjamin; Hummel, Shay; Aharonov, Ranit; Slonim, Noam (2017). "Unsupervised corpus-wide claim detection". Proceedings of the 4th Workshop on Argumentation Mining 2017: 79–84. doi: 10.18653/v1/W17-5110 . S2CID 12346560.
| | This computational linguistics-related article is a stub. You can help Wikipedia by expanding it. |