
In computer science, the analysis of algorithms is the process of finding the computational complexity of algorithms—the amount of time, storage, or other resources needed to execute them. Usually, this involves determining a function that relates the size of an algorithm's input to the number of steps it takes or the number of storage locations it uses. An algorithm is said to be efficient when this function's values are small, or grow slowly compared to a growth in the size of the input. Different inputs of the same size may cause the algorithm to have different behavior, so best, worst and average case descriptions might all be of practical interest. When not otherwise specified, the function describing the performance of an algorithm is usually an upper bound, determined from the worst case inputs to the algorithm.
In computer science, the computational complexity or simply complexity of an algorithm is the amount of resources required to run it. Particular focus is given to computation time and memory storage requirements. The complexity of a problem is the complexity of the best algorithms that allow solving the problem.

In computer science, merge sort is an efficient, general-purpose, and comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the relative order of equal elements is the same in the input and output. Merge sort is a divide-and-conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up merge sort appeared in a report by Goldstine and von Neumann as early as 1948.

In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.

In computer science, Prim's algorithm is a greedy algorithm that finds a minimum spanning tree for a weighted undirected graph. This means it finds a subset of the edges that forms a tree that includes every vertex, where the total weight of all the edges in the tree is minimized. The algorithm operates by building this tree one vertex at a time, from an arbitrary starting vertex, at each step adding the cheapest possible connection from the tree to another vertex.
In computational complexity theory, a decision problem is P-complete if it is in P and every problem in P can be reduced to it by an appropriate reduction.
In computer science, algorithmic efficiency is a property of an algorithm which relates to the amount of computational resources used by the algorithm. Algorithmic efficiency can be thought of as analogous to engineering productivity for a repeating or continuous process.
In computer science, divide and conquer is an algorithm design paradigm. A divide-and-conquer algorithm recursively breaks down a problem into two or more sub-problems of the same or related type, until these become simple enough to be solved directly. The solutions to the sub-problems are then combined to give a solution to the original problem.
In theoretical computer science, the time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. Time complexity is commonly estimated by counting the number of elementary operations performed by the algorithm, supposing that each elementary operation takes a fixed amount of time to perform. Thus, the amount of time taken and the number of elementary operations performed by the algorithm are taken to be related by a constant factor.
In computer science, a graph is an abstract data type that is meant to implement the undirected graph and directed graph concepts from the field of graph theory within mathematics.
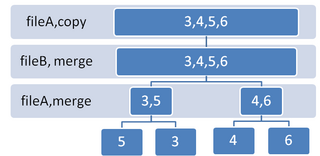
External sorting is a class of sorting algorithms that can handle massive amounts of data. External sorting is required when the data being sorted do not fit into the main memory of a computing device and instead they must reside in the slower external memory, usually a disk drive. Thus, external sorting algorithms are external memory algorithms and thus applicable in the external memory model of computation.

Quicksort is an efficient, general-purpose sorting algorithm. Quicksort was developed by British computer scientist Tony Hoare in 1959 and published in 1961. It is still a commonly used algorithm for sorting. Overall, it is slightly faster than merge sort and heapsort for randomized data, particularly on larger distributions.
In computer science, an algorithm is said to be asymptotically optimal if, roughly speaking, for large inputs it performs at worst a constant factor worse than the best possible algorithm. It is a term commonly encountered in computer science research as a result of widespread use of big-O notation.

In computer architecture, Gustafson's law gives the speedup in the execution time of a task that theoretically gains from parallel computing, using a hypothetical run of the task on a single-core machine as the baseline. To put it another way, it is the theoretical "slowdown" of an already parallelized task if running on a serial machine. It is named after computer scientist John L. Gustafson and his colleague Edwin H. Barsis, and was presented in the article Reevaluating Amdahl's Law in 1988.
In computer science, the prefix sum, cumulative sum, inclusive scan, or simply scan of a sequence of numbers x0, x1, x2, ... is a second sequence of numbers y0, y1, y2, ..., the sums of prefixes of the input sequence:
In parallel computing, work stealing is a scheduling strategy for multithreaded computer programs. It solves the problem of executing a dynamically multithreaded computation, one that can "spawn" new threads of execution, on a statically multithreaded computer, with a fixed number of processors. It does so efficiently in terms of execution time, memory usage, and inter-processor communication.
In computer science, the analysis of parallel algorithms is the process of finding the computational complexity of algorithms executed in parallel – the amount of time, storage, or other resources needed to execute them. In many respects, analysis of parallel algorithms is similar to the analysis of sequential algorithms, but is generally more involved because one must reason about the behavior of multiple cooperating threads of execution. One of the primary goals of parallel analysis is to understand how a parallel algorithm's use of resources changes as the number of processors is changed.
In the design and analysis of algorithms for combinatorial optimization, parametric search is a technique invented by Nimrod Megiddo for transforming a decision algorithm into an optimization algorithm. It is frequently used for solving optimization problems in computational geometry.
In computer science, the reduction operator is a type of operator that is commonly used in parallel programming to reduce the elements of an array into a single result. Reduction operators are associative and often commutative. The reduction of sets of elements is an integral part of programming models such as Map Reduce, where a reduction operator is applied (mapped) to all elements before they are reduced. Other parallel algorithms use reduction operators as primary operations to solve more complex problems. Many reduction operators can be used for broadcasting to distribute data to all processors.
A central problem in algorithmic graph theory is the shortest path problem. Hereby, the problem of finding the shortest path between every pair of nodes is known as all-pair-shortest-paths (APSP) problem. As sequential algorithms for this problem often yield long runtimes, parallelization has shown to be beneficial in this field. In this article two efficient algorithms solving this problem are introduced.


