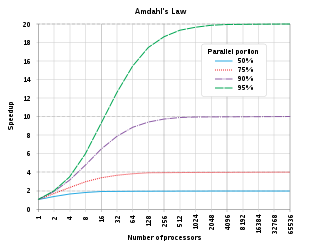
In computer architecture, Amdahl's law is a formula which gives the theoretical speedup in latency of the execution of a task at fixed workload that can be expected of a system whose resources are improved. It states that "the overall performance improvement gained by optimizing a single part of a system is limited by the fraction of time that the improved part is actually used". It is named after computer scientist Gene Amdahl, and was presented at the American Federation of Information Processing Societies (AFIPS) Spring Joint Computer Conference in 1967.
In viscous fluid dynamics, the Archimedes number (Ar), is a dimensionless number used to determine the motion of fluids due to density differences, named after the ancient Greek scientist and mathematician Archimedes.

The Rankine–Hugoniot conditions, also referred to as Rankine–Hugoniot jump conditions or Rankine–Hugoniot relations, describe the relationship between the states on both sides of a shock wave or a combustion wave in a one-dimensional flow in fluids or a one-dimensional deformation in solids. They are named in recognition of the work carried out by Scottish engineer and physicist William John Macquorn Rankine and French engineer Pierre Henri Hugoniot.

In thermodynamics, the Onsager reciprocal relations express the equality of certain ratios between flows and forces in thermodynamic systems out of equilibrium, but where a notion of local equilibrium exists.
The representation theory of groups is a part of mathematics which examines how groups act on given structures.
In mathematical statistics, the Kullback–Leibler (KL) divergence, denoted , is a type of statistical distance: a measure of how one probability distribution P is different from a second, reference probability distribution Q. A simple interpretation of the KL divergence of P from Q is the expected excess surprise from using Q as a model instead of P when the actual distribution is P. While it is a measure of how different two distributions are, and in some sense is thus a "distance", it is not actually a metric, which is the most familiar and formal type of distance. In particular, it is not symmetric in the two distributions, and does not satisfy the triangle inequality. Instead, in terms of information geometry, it is a type of divergence, a generalization of squared distance, and for certain classes of distributions, it satisfies a generalized Pythagorean theorem.

Euler–Bernoulli beam theory is a simplification of the linear theory of elasticity which provides a means of calculating the load-carrying and deflection characteristics of beams. It covers the case corresponding to small deflections of a beam that is subjected to lateral loads only. By ignoring the effects of shear deformation and rotatory inertia, it is thus a special case of Timoshenko–Ehrenfest beam theory. It was first enunciated circa 1750, but was not applied on a large scale until the development of the Eiffel Tower and the Ferris wheel in the late 19th century. Following these successful demonstrations, it quickly became a cornerstone of engineering and an enabler of the Second Industrial Revolution.

In electromagnetism, charge density is the amount of electric charge per unit length, surface area, or volume. Volume charge density is the quantity of charge per unit volume, measured in the SI system in coulombs per cubic meter (C⋅m−3), at any point in a volume. Surface charge density (σ) is the quantity of charge per unit area, measured in coulombs per square meter (C⋅m−2), at any point on a surface charge distribution on a two dimensional surface. Linear charge density (λ) is the quantity of charge per unit length, measured in coulombs per meter (C⋅m−1), at any point on a line charge distribution. Charge density can be either positive or negative, since electric charge can be either positive or negative.

In computer architecture, Gustafson's law gives the speedup in the execution time of a task that theoretically gains from parallel computing, using a hypothetical run of the task on a single-core machine as the baseline. To put it another way, it is the theoretical "slowdown" of an already parallelized task if running on a serial machine. It is named after computer scientist John L. Gustafson and his colleague Edwin H. Barsis, and was presented in the article Reevaluating Amdahl's Law in 1988.
In quantum information theory, quantum relative entropy is a measure of distinguishability between two quantum states. It is the quantum mechanical analog of relative entropy.
An autoencoder is a type of artificial neural network used to learn efficient codings of unlabeled data. An autoencoder learns two functions: an encoding function that transforms the input data, and a decoding function that recreates the input data from the encoded representation. The autoencoder learns an efficient representation (encoding) for a set of data, typically for dimensionality reduction.
In atmospheric thermodynamics, the virtual temperature of a moist air parcel is the temperature at which a theoretical dry air parcel would have a total pressure and density equal to the moist parcel of air. The virtual temperature of unsaturated moist air is always greater than the absolute air temperature, however, as the existence of suspended cloud droplets reduces the virtual temperature.
In queueing theory, a discipline within the mathematical theory of probability, the Pollaczek–Khinchine formula states a relationship between the queue length and service time distribution Laplace transforms for an M/G/1 queue. The term is also used to refer to the relationships between the mean queue length and mean waiting/service time in such a model.
Within theoretical computer science, the Sun–Ni law is a memory-bounded speedup model which states that as computing power increases the corresponding increase in problem size is constrained by the system’s memory capacity. In general, as a system grows in computational power, the problems run on the system increase in size. Analogous to Amdahl's law, which says that the problem size remains constant as system sizes grow, and Gustafson's law, which proposes that the problem size should scale but be bound by a fixed amount of time, the Sun–Ni law states the problem size should scale but be bound by the memory capacity of the system. Sun–Ni law was initially proposed by Xian-He Sun and Lionel Ni at the Proceedings of IEEE Supercomputing Conference 1990.
In queueing theory, a discipline within the mathematical theory of probability, the M/M/c queue is a multi-server queueing model. In Kendall's notation it describes a system where arrivals form a single queue and are governed by a Poisson process, there are c servers, and job service times are exponentially distributed. It is a generalisation of the M/M/1 queue which considers only a single server. The model with infinitely many servers is the M/M/∞ queue.

In fluid dynamics, the Reynolds number is a dimensionless quantity that helps predict fluid flow patterns in different situations by measuring the ratio between inertial and viscous forces. At low Reynolds numbers, flows tend to be dominated by laminar (sheet-like) flow, while at high Reynolds numbers, flows tend to be turbulent. The turbulence results from differences in the fluid's speed and direction, which may sometimes intersect or even move counter to the overall direction of the flow. These eddy currents begin to churn the flow, using up energy in the process, which for liquids increases the chances of cavitation.
An electric dipole transition is the dominant effect of an interaction of an electron in an atom with the electromagnetic field.

Sea ice is a complex composite composed primarily of pure ice in various states of crystallization, but including air bubbles and pockets of brine. Understanding its growth processes is important for climate modellers and remote sensing specialists, since the composition and microstructural properties of the ice affect how it reflects or absorbs sunlight.
In computing and communication systems, a work-conserving scheduler is a scheduler that always tries to keep the scheduled resource(s) busy, if there are submitted jobs ready to be scheduled. In contrast, a non-work conserving scheduler is a scheduler that, in some cases, may leave the scheduled resource(s) idle despite the presence of jobs ready to be scheduled.
In machine learning, diffusion models, also known as diffusion probabilistic models or score-based generative models, are a class of latent variable generative models. A diffusion model consists of three major components: the forward process, the reverse process, and the sampling procedure. The goal of diffusion models is to learn a diffusion process that generates a probability distribution for a given dataset from which we can then sample new images. They learn the latent structure of a dataset by modeling the way in which data points diffuse through their latent space.







