Related Research Articles
Distributed computing is a field of computer science that studies distributed systems, defined as computer systems whose inter-communicating components are located on different networked computers.

Symmetric multiprocessing or shared-memory multiprocessing (SMP) involves a multiprocessor computer hardware and software architecture where two or more identical processors are connected to a single, shared main memory, have full access to all input and output devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
Multiprocessing is the use of two or more central processing units (CPUs) within a single computer system. The term also refers to the ability of a system to support more than one processor or the ability to allocate tasks between them. There are many variations on this basic theme, and the definition of multiprocessing can vary with context, mostly as a function of how CPUs are defined.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
In computer science, a parallel algorithm, as opposed to a traditional serial algorithm, is an algorithm which can do multiple operations in a given time. It has been a tradition of computer science to describe serial algorithms in abstract machine models, often the one known as random-access machine. Similarly, many computer science researchers have used a so-called parallel random-access machine (PRAM) as a parallel abstract machine (shared-memory).
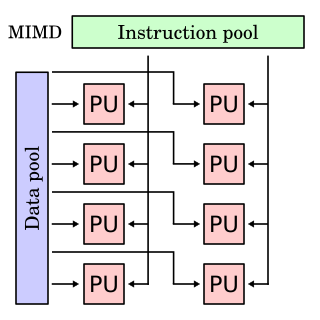
In computing, multiple instruction, multiple data (MIMD) is a technique employed to achieve parallelism. Machines using MIMD have a number of processors that function asynchronously and independently. At any time, different processors may be executing different instructions on different pieces of data.

In computer science, distributed memory refers to a multiprocessor computer system in which each processor has its own private memory. Computational tasks can only operate on local data, and if remote data are required, the computational task must communicate with one or more remote processors. In contrast, a shared memory multiprocessor offers a single memory space used by all processors. Processors do not have to be aware where data resides, except that there may be performance penalties, and that race conditions are to be avoided.

Cleve Barry Moler is an American mathematician and computer programmer specializing in numerical analysis. In the mid to late 1970s, he was one of the authors of LINPACK and EISPACK, Fortran libraries for numerical computing. He created MATLAB, a numerical computing package, to give his students at the University of New Mexico easy access to these libraries without writing Fortran. In 1984, he co-founded MathWorks with Jack Little to commercialize this program.

In computer science, concurrency is the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the outcome. This allows for parallel execution of the concurrent units, which can significantly improve overall speed of the execution in multi-processor and multi-core systems. In more technical terms, concurrency refers to the decomposability of a program, algorithm, or problem into order-independent or partially-ordered components or units of computation.
In computing, single program, multiple data (SPMD) is a term that has been used to refer to computational models for exploiting parallelism where-by multiple processors cooperate in the execution of a program in order to obtain results faster.
General-purpose computing on graphics processing units is the use of a graphics processing unit (GPU), which typically handles computation only for computer graphics, to perform computation in applications traditionally handled by the central processing unit (CPU). The use of multiple video cards in one computer, or large numbers of graphics chips, further parallelizes the already parallel nature of graphics processing.
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.

A multi-core processor is a microprocessor on a single integrated circuit with two or more separate processing units, called cores, each of which reads and executes program instructions. The instructions are ordinary CPU instructions but the single processor can run instructions on separate cores at the same time, increasing overall speed for programs that support multithreading or other parallel computing techniques. Manufacturers typically integrate the cores onto a single integrated circuit die or onto multiple dies in a single chip package. The microprocessors currently used in almost all personal computers are multi-core.
Shahid H. Bokhari is a highly cited Pakistani researcher in the field of parallel and distributed computing. He is a fellow of both IEEE and ACM. Bokhari's ACM Fellow citation states that he received the award for his "research contributions to automatic load balancing and partitioning of distributed processes", while his IEEE Fellow award recognises his "contributions to the mapping problem in parallel and distributed computing".
The Intel Personal SuperComputer was a product line of parallel computers in the 1980s and 1990s. The iPSC/1 was superseded by the Intel iPSC/2, and then the Intel iPSC/860.

A computer cluster is a set of computers that work together so that they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software. The newest manifestation of cluster computing is cloud computing.
Data-intensive computing is a class of parallel computing applications which use a data parallel approach to process large volumes of data typically terabytes or petabytes in size and typically referred to as big data. Computing applications that devote most of their execution time to computational requirements are deemed compute-intensive, whereas applications are deemed data-intensive require large volumes of data and devote most of their processing time to I/O and manipulation of data.

Tachyon is a parallel/multiprocessor ray tracing software. It is a parallel ray tracing library for use on distributed memory parallel computers, shared memory computers, and clusters of workstations. Tachyon implements rendering features such as ambient occlusion lighting, depth-of-field focal blur, shadows, reflections, and others. It was originally developed for the Intel iPSC/860 by John Stone for his M.S. thesis at University of Missouri-Rolla. Tachyon subsequently became a more functional and complete ray tracing engine, and it is now incorporated into a number of other open source software packages such as VMD, and SageMath. Tachyon is released under a permissive license.
Massively parallel is the term for using a large number of computer processors to simultaneously perform a set of coordinated computations in parallel. GPUs are massively parallel architecture with tens of thousands of threads.
References
- ↑ Herlihy, Maurice; Shavit, Nir (2012). The Art of Multiprocessor Programming, Revised Reprint (revised ed.). Elsevier. p. 14. ISBN 9780123977953 . Retrieved 28 February 2016.
Some computational problems are "embarrassingly parallel": they can easily be divided into components that can be executed concurrently.
- ↑ Section 1.4.4 of: Foster, Ian (1995). Designing and Building Parallel Programs. Addison–Wesley. ISBN 9780201575941. Archived from the original on 2011-03-01.
- ↑ Alan Chalmers; Erik Reinhard; Tim Davis (21 March 2011). Practical Parallel Rendering. CRC Press. ISBN 978-1-4398-6380-0.
- ↑ Matloff, Norman (2011). The Art of R Programming: A Tour of Statistical Software Design, p.347. No Starch. ISBN 9781593274108.
- ↑ Leykin, Anton; Verschelde, Jan; Zhuang, Yan (2006). "Parallel Homotopy Algorithms to Solve Polynomial Systems". Mathematical Software - ICMS 2006. Lecture Notes in Computer Science. Vol. 4151. pp. 225–234. doi:10.1007/11832225_22. ISBN 978-3-540-38084-9.
- ↑ Moler, Cleve (1986). "Matrix Computation on Distributed Memory Multiprocessors". In Heath, Michael T. (ed.). Hypercube Multiprocessors. Society for Industrial and Applied Mathematics, Philadelphia. ISBN 978-0898712094.
- ↑ The Intel hypercube part 2 reposted on Cleve's Corner blog on The MathWorks website
- ↑ Kepner, Jeremy (2009). Parallel MATLAB for Multicore and Multinode Computers, p.12. SIAM. ISBN 9780898716733.
- ↑ Erricos John Kontoghiorghes (21 December 2005). Handbook of Parallel Computing and Statistics. CRC Press. ISBN 978-1-4200-2868-3.
- ↑ Yuefan Deng (2013). Applied Parallel Computing. World Scientific. ISBN 978-981-4307-60-4.
- ↑ Josefsson, Simon; Percival, Colin (August 2016). "The scrypt Password-Based Key Derivation Function". tools.ietf.org. doi:10.17487/RFC7914 . Retrieved 2016-12-12.
- ↑ Mathog, DR (22 September 2003). "Parallel BLAST on split databases". Bioinformatics. 19 (14): 1865–6. doi: 10.1093/bioinformatics/btg250 . PMID 14512366.
- ↑ How we made our face recognizer 25 times faster (developer blog post)
- ↑ Shigeyoshi Tsutsui; Pierre Collet (5 December 2013). Massively Parallel Evolutionary Computation on GPGPUs. Springer Science & Business Media. ISBN 978-3-642-37959-8.
- ↑ Youssef Hamadi; Lakhdar Sais (5 April 2018). Handbook of Parallel Constraint Reasoning. Springer. ISBN 978-3-319-63516-3.
- ↑ Simple Network of Workstations (SNOW) package