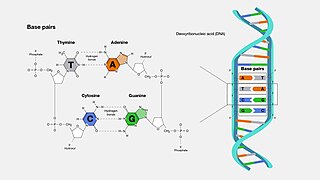
A base pair (bp) is a fundamental unit of double-stranded nucleic acids consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, "Watson–Crick" base pairs allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.

Deoxyribonucleic acid is a polymer composed of two polynucleotide chains that coil around each other to form a double helix. The polymer carries genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses. DNA and ribonucleic acid (RNA) are nucleic acids. Alongside proteins, lipids and complex carbohydrates (polysaccharides), nucleic acids are one of the four major types of macromolecules that are essential for all known forms of life.

Nucleic acids are large biomolecules that are crucial in all cells and viruses. They are composed of nucleotides, which are the monomer components: a 5-carbon sugar, a phosphate group and a nitrogenous base. The two main classes of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). If the sugar is ribose, the polymer is RNA; if the sugar is deoxyribose, a variant of ribose, the polymer is DNA.

Nucleotides are organic molecules composed of a nitrogenous base, a pentose sugar and a phosphate. They serve as monomeric units of the nucleic acid polymers – deoxyribonucleic acid (DNA) and ribonucleic acid (RNA), both of which are essential biomolecules within all life-forms on Earth. Nucleotides are obtained in the diet and are also synthesized from common nutrients by the liver.

Nucleobases are nitrogen-containing biological compounds that form nucleosides, which, in turn, are components of nucleotides, with all of these monomers constituting the basic building blocks of nucleic acids. The ability of nucleobases to form base pairs and to stack one upon another leads directly to long-chain helical structures such as ribonucleic acid (RNA) and deoxyribonucleic acid (DNA). Five nucleobases—adenine (A), cytosine (C), guanine (G), thymine (T), and uracil (U)—are called primary or canonical. They function as the fundamental units of the genetic code, with the bases A, G, C, and T being found in DNA while A, G, C, and U are found in RNA. Thymine and uracil are distinguished by merely the presence or absence of a methyl group on the fifth carbon (C5) of these heterocyclic six-membered rings. In addition, some viruses have aminoadenine (Z) instead of adenine. It differs in having an extra amine group, creating a more stable bond to thymine.
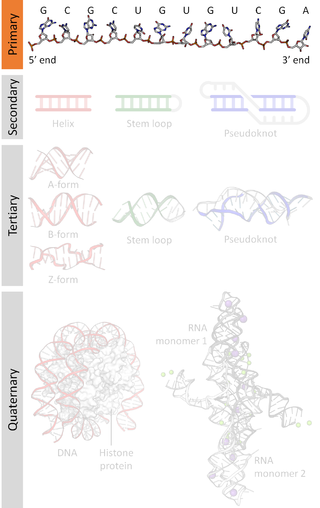
A nucleic acid sequence is a succession of bases within the nucleotides forming alleles within a DNA or RNA (GACU) molecule. This succession is denoted by a series of a set of five different letters that indicate the order of the nucleotides. By convention, sequences are usually presented from the 5' end to the 3' end. For DNA, with its double helix, there are two possible directions for the notated sequence; of these two, the sense strand is used. Because nucleic acids are normally linear (unbranched) polymers, specifying the sequence is equivalent to defining the covalent structure of the entire molecule. For this reason, the nucleic acid sequence is also termed the primary structure.

DNA synthesis is the natural or artificial creation of deoxyribonucleic acid (DNA) molecules. DNA is a macromolecule made up of nucleotide units, which are linked by covalent bonds and hydrogen bonds, in a repeating structure. DNA synthesis occurs when these nucleotide units are joined to form DNA; this can occur artificially or naturally. Nucleotide units are made up of a nitrogenous base, pentose sugar (deoxyribose) and phosphate group. Each unit is joined when a covalent bond forms between its phosphate group and the pentose sugar of the next nucleotide, forming a sugar-phosphate backbone. DNA is a complementary, double stranded structure as specific base pairing occurs naturally when hydrogen bonds form between the nucleotide bases.

In biochemistry, a ribonucleotide is a nucleotide containing ribose as its pentose component. It is considered a molecular precursor of nucleic acids. Nucleotides are the basic building blocks of DNA and RNA. Ribonucleotides themselves are basic monomeric building blocks for RNA. Deoxyribonucleotides, formed by reducing ribonucleotides with the enzyme ribonucleotide reductase (RNR), are essential building blocks for DNA. There are several differences between DNA deoxyribonucleotides and RNA ribonucleotides. Successive nucleotides are linked together via phosphodiester bonds.
A nucleoside triphosphate is a nucleoside containing a nitrogenous base bound to a 5-carbon sugar, with three phosphate groups bound to the sugar. They are the molecular precursors of both DNA and RNA, which are chains of nucleotides made through the processes of DNA replication and transcription. Nucleoside triphosphates also serve as a source of energy for cellular reactions and are involved in signalling pathways.
Xenobiology (XB) is a subfield of synthetic biology, the study of synthesizing and manipulating biological devices and systems. The name "xenobiology" derives from the Greek word xenos, which means "stranger, alien". Xenobiology is a form of biology that is not (yet) familiar to science and is not found in nature. In practice, it describes novel biological systems and biochemistries that differ from the canonical DNA–RNA-20 amino acid system. For example, instead of DNA or RNA, XB explores nucleic acid analogues, termed xeno nucleic acid (XNA) as information carriers. It also focuses on an expanded genetic code and the incorporation of non-proteinogenic amino acids, or “xeno amino acids” into proteins.

Isoguanine or 2-hydroxyadenine is a purine base that is an isomer of guanine. It is a product of oxidative damage to DNA and has been shown to cause mutation. It is also used in combination with isocytosine in studies of unnatural nucleic acid analogues of the normal base pairs in DNA.
Artificially Expanded Genetic Information System (AEGIS) is a synthetic DNA analog experiment that uses some unnatural base pairs from the laboratories of the Foundation for Applied Molecular Evolution in Gainesville, Florida. AEGIS is a NASA-funded project to try to understand how extraterrestrial life may have developed.

Nucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary, and quaternary.

Nucleic acid secondary structure is the basepairing interactions within a single nucleic acid polymer or between two polymers. It can be represented as a list of bases which are paired in a nucleic acid molecule. The secondary structures of biological DNAs and RNAs tend to be different: biological DNA mostly exists as fully base paired double helices, while biological RNA is single stranded and often forms complex and intricate base-pairing interactions due to its increased ability to form hydrogen bonds stemming from the extra hydroxyl group in the ribose sugar.
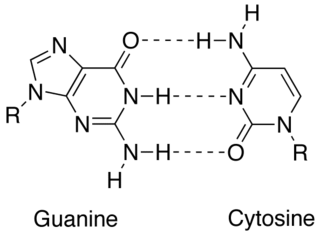
In molecular biology, complementarity describes a relationship between two structures each following the lock-and-key principle. In nature complementarity is the base principle of DNA replication and transcription as it is a property shared between two DNA or RNA sequences, such that when they are aligned antiparallel to each other, the nucleotide bases at each position in the sequences will be complementary, much like looking in the mirror and seeing the reverse of things. This complementary base pairing allows cells to copy information from one generation to another and even find and repair damage to the information stored in the sequences.
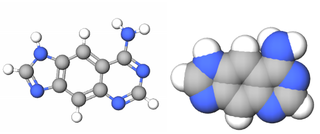
xDNA is a size-expanded nucleotide system synthesized from the fusion of a benzene ring and one of the four natural bases: adenine, guanine, cytosine, and thymine. This size expansion produces an 8 letter alphabet which has a larger information storage capacity than natural DNA's 4 letter alphabet. As with normal base-pairing, A pairs with xT, C pairs with xG, G pairs with xC, and T pairs with xA. The double helix is thus 2.4Å wider than a natural double helix. While similar in structure to B-DNA, xDNA has unique absorption, fluorescence, and stacking properties.

Xeno nucleic acids (XNA) are synthetic nucleic acid analogues that have a different backbone than the ribose and deoxyribose found in the nucleic acids of naturally occurring RNA and DNA.

Hachimoji DNA is a synthetic nucleic acid analog that uses four synthetic nucleotides in addition to the four present in the natural nucleic acids, DNA and RNA. This leads to four allowed base pairs: two unnatural base pairs formed by the synthetic nucleobases in addition to the two normal pairs. Hachimoji bases have been demonstrated in both DNA and RNA analogs, using deoxyribose and ribose respectively as the backbone sugar.
This glossary of cellular and molecular biology is a list of definitions of terms and concepts commonly used in the study of cell biology, molecular biology, and related disciplines, including genetics, biochemistry, and microbiology. It is split across two articles:
This glossary of cellular and molecular biology is a list of definitions of terms and concepts commonly used in the study of cell biology, molecular biology, and related disciplines, including genetics, biochemistry, and microbiology. It is split across two articles:













