Polyadenylation is the addition of a poly(A) tail to an RNA transcript, typically a messenger RNA (mRNA). The poly(A) tail consists of multiple adenosine monophosphates; in other words, it is a stretch of RNA that has only adenine bases. In eukaryotes, polyadenylation is part of the process that produces mature mRNA for translation. In many bacteria, the poly(A) tail promotes degradation of the mRNA. It, therefore, forms part of the larger process of gene expression.

Tryptophan repressor is a transcription factor involved in controlling amino acid metabolism. It has been best studied in Escherichia coli, where it is a dimeric protein that regulates transcription of the 5 genes in the tryptophan operon. When the amino acid tryptophan is plentiful in the cell, it binds to the protein, which causes a conformational change in the protein. The repressor complex then binds to its operator sequence in the genes it regulates, shutting off the genes.

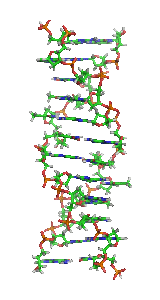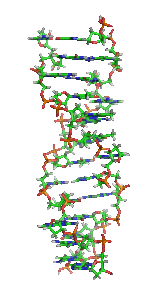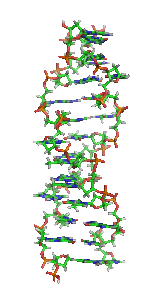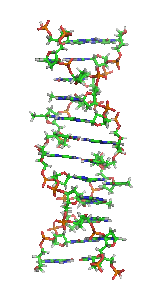
In molecular biology, the term double helix refers to the structure formed by double-stranded molecules of nucleic acids such as DNA. The double helical structure of a nucleic acid complex arises as a consequence of its secondary structure, and is a fundamental component in determining its tertiary structure.The structure was discovered by Rosalind Franklin and her student Raymond Gosling, but the term "double helix" entered popular culture with the publication in 1968 of The Double Helix: A Personal Account of the Discovery of the Structure of DNA by James Watson.
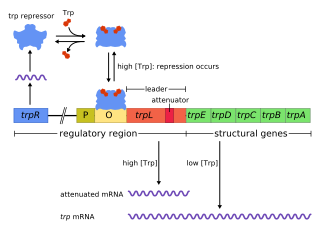
The trp operon is a group of genes that are transcribed together, encoding the enzymes that produce the amino acid tryptophan in bacteria. The trp operon was first characterized in Escherichia coli, and it has since been discovered in many other bacteria. The operon is regulated so that, when tryptophan is present in the environment, the genes for tryptophan synthesis are repressed.
Alexander Rich was an American biologist and biophysicist. He was the William Thompson Sedgwick Professor of Biophysics at MIT and Harvard Medical School. Rich earned an A.B. and an M.D. from Harvard University. He was a post-doc of Linus Pauling. During this time he was a member of the RNA Tie Club, a social and discussion group which attacked the question of how DNA encodes proteins. He had over 600 publications to his name.

The restriction endonuclease Fok1, naturally found in Flavobacterium okeanokoites, is a bacterial type IIS restriction endonuclease consisting of an N-terminal DNA-binding domain and a non sequence-specific DNA cleavage domain at the C-terminal. Once the protein is bound to duplex DNA via its DNA-binding domain at the 5'-GGATG-3' recognition site, the DNA cleavage domain is activated and cleaves the DNA at two locations, regardless of the nucleotide sequence at the cut site. The DNA is cut 9 nucleotides downstream of the motif on the forward strand, and 13 nucleotides downstream of the motif on the reverse strand, producing two sticky ends with 4-bp overhangs.

N-myc proto-oncogene protein also known as N-Myc or basic helix-loop-helix protein 37 (bHLHe37), is a protein that in humans is encoded by the MYCN gene.
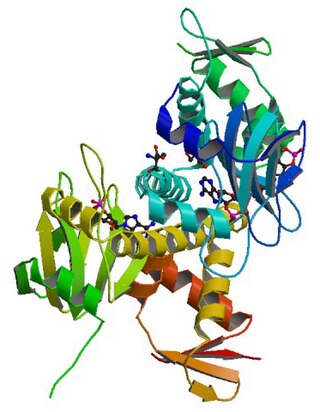
cAMP receptor protein is a regulatory protein in bacteria. CRP protein binds cAMP, which causes a conformational change that allows CRP to bind tightly to a specific DNA site in the promoters of the genes it controls. CRP then activates transcription through direct protein–protein interactions with RNA polymerase.

Eukaryotic transcription is the elaborate process that eukaryotic cells use to copy genetic information stored in DNA into units of transportable complementary RNA replica. Gene transcription occurs in both eukaryotic and prokaryotic cells. Unlike prokaryotic RNA polymerase that initiates the transcription of all different types of RNA, RNA polymerase in eukaryotes comes in three variations, each translating a different type of gene. A eukaryotic cell has a nucleus that separates the processes of transcription and translation. Eukaryotic transcription occurs within the nucleus where DNA is packaged into nucleosomes and higher order chromatin structures. The complexity of the eukaryotic genome necessitates a great variety and complexity of gene expression control.

Poly(rC)-binding protein 1 is a protein that in humans is encoded by the PCBP1 gene.

The double-stranded RNA-specific adenosine deaminase enzyme family are encoded by the ADAR family genes. ADAR stands for adenosine deaminase acting on RNA. This article focuses on the ADAR proteins; This article details the evolutionary history, structure, function, mechanisms and importance of all proteins within this family.

Ras GTPase-activating protein-binding protein 1 is an enzyme that in humans is encoded by the G3BP1 gene.

DNA-binding protein A is a protein that in humans is encoded by the CSDA gene.

Poly(rC)-binding protein 3 is a protein that in humans is encoded by the PCBP3 gene.

Transcriptional repressor NF-X1 is a protein that in humans is encoded by the NFX1 gene.

Z-DNA-binding protein 1, also known as DNA-dependent activator of IFN-regulatory factors (DAI) and DLM-1, is a protein that in humans is encoded by the ZBP1 gene.

The B recognition element (BRE) is a DNA sequence found in the promoter region of most genes in eukaryotes and Archaea. The BRE is a cis-regulatory element that is found immediately near TATA box, and consists of 7 nucleotides. There are two sets of BREs: one (BREu) found immediately upstream of the TATA box, with the consensus SSRCGCC; the other (BREd) found around 7 nucleotides downstream, with the consensus RTDKKKK.
Zinc finger transcription factors or ZF-TFs, are transcription factors composed of a zinc finger-binding domain and any of a variety of transcription-factor effector-domains that exert their modulatory effect in the vicinity of any sequence to which the protein domain binds.

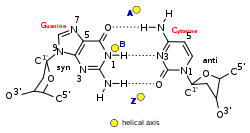
In molecular biology, the protein domain Adenosine deaminase z-alpha domain refers to an evolutionary conserved protein domain. This family consists of the N-terminus and thus the z-alpha domain of double-stranded RNA-specific adenosine deaminase (ADAR), an RNA-editing enzyme. The z-alpha domain is a Z-DNA binding domain, and binding of this region to B-DNA has been shown to be disfavoured by steric hindrance.
Kevin Struhl is an American molecular biologist and the David Wesley Gaiser Professor of Biological Chemistry and Molecular Pharmacology at Harvard Medical School. Struhl is primarily known for his work on transcriptional regulatory mechanisms in yeast using molecular, genetic, biochemical, and genomic approaches. More recently, he has used related approaches to study transcriptional regulatory circuits involved in cellular transformation and the formation of cancer stem cells.