In mathematics, a reflection is a mapping from a Euclidean space to itself that is an isometry with a hyperplane as a set of fixed points; this set is called the axis or plane of reflection. The image of a figure by a reflection is its mirror image in the axis or plane of reflection. For example the mirror image of the small Latin letter p for a reflection with respect to a vertical axis would look like q. Its image by reflection in a horizontal axis would look like b. A reflection is an involution: when applied twice in succession, every point returns to its original location, and every geometrical object is restored to its original state.

A 3D projection is a design technique used to display a three-dimensional (3D) object on a two-dimensional (2D) surface. These projections rely on visual perspective and aspect analysis to project a complex object for viewing capability on a simpler plane.

Curve fitting is the process of constructing a curve, or mathematical function, that has the best fit to a series of data points, possibly subject to constraints. Curve fitting can involve either interpolation, where an exact fit to the data is required, or smoothing, in which a "smooth" function is constructed that approximately fits the data. A related topic is regression analysis, which focuses more on questions of statistical inference such as how much uncertainty is present in a curve that is fitted to data observed with random errors. Fitted curves can be used as an aid for data visualization, to infer values of a function where no data are available, and to summarize the relationships among two or more variables. Extrapolation refers to the use of a fitted curve beyond the range of the observed data, and is subject to a degree of uncertainty since it may reflect the method used to construct the curve as much as it reflects the observed data.
In linear algebra, linear transformations can be represented by matrices. If is a linear transformation mapping to and is a column vector with entries, then
The scale-invariant feature transform (SIFT) is a computer vision algorithm to detect, describe, and match local features in images, invented by David Lowe in 1999. Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, individual identification of wildlife and match moving.
In visual effects, match moving is a technique that allows the insertion of 2D elements, other live action elements or CG computer graphics into live-action footage with correct position, scale, orientation, and motion relative to the photographed objects in the shot. It also allows for the removal of live action elements from the live action shot. The term is used loosely to describe several different methods of extracting camera motion information from a motion picture. Sometimes referred to as motion tracking or camera solving, match moving is related to rotoscoping and photogrammetry. Match moving is sometimes confused with motion capture, which records the motion of objects, often human actors, rather than the camera. Typically, motion capture requires special cameras and sensors and a controlled environment. Match moving is also distinct from motion control photography, which uses mechanical hardware to execute multiple identical camera moves. Match moving, by contrast, is typically a software-based technology, applied after the fact to normal footage recorded in uncontrolled environments with an ordinary camera.

Geometry processing is an area of research that uses concepts from applied mathematics, computer science and engineering to design efficient algorithms for the acquisition, reconstruction, analysis, manipulation, simulation and transmission of complex 3D models. As the name implies, many of the concepts, data structures, and algorithms are directly analogous to signal processing and image processing. For example, where image smoothing might convolve an intensity signal with a blur kernel formed using the Laplace operator, geometric smoothing might be achieved by convolving a surface geometry with a blur kernel formed using the Laplace-Beltrami operator.

Image stitching or photo stitching is the process of combining multiple photographic images with overlapping fields of view to produce a segmented panorama or high-resolution image. Commonly performed through the use of computer software, most approaches to image stitching require nearly exact overlaps between images and identical exposures to produce seamless results, although some stitching algorithms actually benefit from differently exposed images by doing high-dynamic-range imaging in regions of overlap. Some digital cameras can stitch their photos internally.
In the fields of computing and computer vision, pose represents the position and orientation of an object, usually in three dimensions. Poses are often stored internally as transformation matrices. The term “pose” is largely synonymous with the term “transform”, but a transform may often include scale, whereas pose does not.
Camera resectioning is the process of estimating the parameters of a pinhole camera model approximating the camera that produced a given photograph or video; it determines which incoming light ray is associated with each pixel on the resulting image. Basically, the process determines the pose of the pinhole camera.

Image rectification is a transformation process used to project images onto a common image plane. This process has several degrees of freedom and there are many strategies for transforming images to the common plane. Image rectification is used in computer stereo vision to simplify the problem of finding matching points between images, and in geographic information systems to merge images taken from multiple perspectives into a common map coordinate system.
The difference-map algorithm is a search algorithm for general constraint satisfaction problems. It is a meta-algorithm in the sense that it is built from more basic algorithms that perform projections onto constraint sets. From a mathematical perspective, the difference-map algorithm is a dynamical system based on a mapping of Euclidean space. Solutions are encoded as fixed points of the mapping.
Compressed sensing is a signal processing technique for efficiently acquiring and reconstructing a signal, by finding solutions to underdetermined linear systems. This is based on the principle that, through optimization, the sparsity of a signal can be exploited to recover it from far fewer samples than required by the Nyquist–Shannon sampling theorem. There are two conditions under which recovery is possible. The first one is sparsity, which requires the signal to be sparse in some domain. The second one is incoherence, which is applied through the isometric property, which is sufficient for sparse signals. Compressed sensing has applications in, for example, MRI where the incoherence condition is typically satisfied.
In computer vision, triangulation refers to the process of determining a point in 3D space given its projections onto two, or more, images. In order to solve this problem it is necessary to know the parameters of the camera projection function from 3D to 2D for the cameras involved, in the simplest case represented by the camera matrices. Triangulation is sometimes also referred to as reconstruction or intersection.
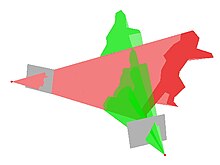
In photogrammetry and computer stereo vision, bundle adjustment is simultaneous refining of the 3D coordinates describing the scene geometry, the parameters of the relative motion, and the optical characteristics of the camera(s) employed to acquire the images, given a set of images depicting a number of 3D points from different viewpoints. Its name refers to the geometrical bundles of light rays originating from each 3D feature and converging on each camera's optical center, which are adjusted optimally according to an optimality criterion involving the corresponding image projections of all points.
In computer vision, 3D object recognition involves recognizing and determining 3D information, such as the pose, volume, or shape, of user-chosen 3D objects in a photograph or range scan. Typically, an example of the object to be recognized is presented to a vision system in a controlled environment, and then for an arbitrary input such as a video stream, the system locates the previously presented object. This can be done either off-line, or in real-time. The algorithms for solving this problem are specialized for locating a single pre-identified object, and can be contrasted with algorithms which operate on general classes of objects, such as face recognition systems or 3D generic object recognition. Due to the low cost and ease of acquiring photographs, a significant amount of research has been devoted to 3D object recognition in photographs.
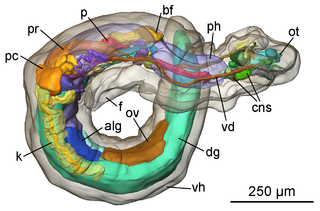
In computer vision and computer graphics, 3D reconstruction is the process of capturing the shape and appearance of real objects. This process can be accomplished either by active or passive methods. If the model is allowed to change its shape in time, this is referred to as non-rigid or spatio-temporal reconstruction.
Camera auto-calibration is the process of determining internal camera parameters directly from multiple uncalibrated images of unstructured scenes. In contrast to classic camera calibration, auto-calibration does not require any special calibration objects in the scene. In the visual effects industry, camera auto-calibration is often part of the "Match Moving" process where a synthetic camera trajectory and intrinsic projection model are solved to reproject synthetic content into video.

In computer vision, pattern recognition, and robotics, point-set registration, also known as point-cloud registration or scan matching, is the process of finding a spatial transformation that aligns two point clouds. The purpose of finding such a transformation includes merging multiple data sets into a globally consistent model, and mapping a new measurement to a known data set to identify features or to estimate its pose. Raw 3D point cloud data are typically obtained from Lidars and RGB-D cameras. 3D point clouds can also be generated from computer vision algorithms such as triangulation, bundle adjustment, and more recently, monocular image depth estimation using deep learning. For 2D point set registration used in image processing and feature-based image registration, a point set may be 2D pixel coordinates obtained by feature extraction from an image, for example corner detection. Point cloud registration has extensive applications in autonomous driving, motion estimation and 3D reconstruction, object detection and pose estimation, robotic manipulation, simultaneous localization and mapping (SLAM), panorama stitching, virtual and augmented reality, and medical imaging.
Perspective-n-Point is the problem of estimating the pose of a calibrated camera given a set of n 3D points in the world and their corresponding 2D projections in the image. The camera pose consists of 6 degrees-of-freedom (DOF) which are made up of the rotation and 3D translation of the camera with respect to the world. This problem originates from camera calibration and has many applications in computer vision and other areas, including 3D pose estimation, robotics and augmented reality. A commonly used solution to the problem exists for n = 3 called P3P, and many solutions are available for the general case of n ≥ 3. A solution for n = 2 exists if feature orientations are available at the two points. Implementations of these solutions are also available in open source software.