Information retrieval (IR) in computing and information science is the process of obtaining information system resources that are relevant to an information need from a collection of those resources. Searches can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for the metadata that describes data, and for databases of texts, images or sounds.
Spamdexing is the deliberate manipulation of search engine indexes. It involves a number of methods, such as link building and repeating unrelated phrases, to manipulate the relevance or prominence of resources indexed in a manner inconsistent with the purpose of the indexing system.
An image retrieval system is a computer system used for browsing, searching and retrieving images from a large database of digital images. Most traditional and common methods of image retrieval utilize some method of adding metadata such as captioning, keywords, title or descriptions to the images so that retrieval can be performed over the annotation words. Manual image annotation is time-consuming, laborious and expensive; to address this, there has been a large amount of research done on automatic image annotation. Additionally, the increase in social web applications and the semantic web have inspired the development of several web-based image annotation tools.

A metasearch engine is an online information retrieval tool that uses the data of a web search engine to produce its own results. Metasearch engines take input from a user and immediately query search engines for results. Sufficient data is gathered, ranked, and presented to the users.
Keyword spotting is a problem that was historically first defined in the context of speech processing. In speech processing, keyword spotting deals with the identification of keywords in utterances.

Automatic image annotation is the process by which a computer system automatically assigns metadata in the form of captioning or keywords to a digital image. This application of computer vision techniques is used in image retrieval systems to organize and locate images of interest from a database.

A tag cloud is a visual representation of text data which is often used to depict keyword metadata on websites, or to visualize free form text. Tags are usually single words, and the importance of each tag is shown with font size or color. When used as website navigation aids, the terms are hyperlinked to items associated with the tag.
A video search engine is a web-based search engine which crawls the web for video content. Some video search engines parse externally hosted content while others allow content to be uploaded and hosted on their own servers. Some engines also allow users to search by video format type and by length of the clip. The video search results are usually accompanied by a thumbnail view of the video.
Search Engine Results Pages (SERP) are the pages displayed by search engines in response to a query by a user. The main component of the SERP is the listing of results that are returned by the search engine in response to a keyword query.
An image organizer or image management application is application software for organising digital images. It is a kind of desktop organizer software application.
Image meta search is a type of search engine specialised on finding pictures, images, animations etc. Like the text search, image search is an information retrieval system designed to help to find information on the Internet and it allows the user to look for images etc. using keywords or search phrases and to receive a set of thumbnail images, sorted by relevancy.
In computer vision, visual descriptors or image descriptors are descriptions of the visual features of the contents in images, videos, or algorithms or applications that produce such descriptions. They describe elementary characteristics such as the shape, the color, the texture or the motion, among others.
An audio search engine is a web-based search engine which crawls the web for audio content. The information can consist of web pages, images, audio files, or another type of document. Various techniques exist for research on these engines.
Artificial imagination is a narrow subcomponent of artificial general intelligence which generates, simulates, and facilitates real or possible fiction models to create predictions, inventions, or conscious experiences.
A concept search is an automated information retrieval method that is used to search electronically stored unstructured text for information that is conceptually similar to the information provided in a search query. In other words, the ideas expressed in the information retrieved in response to a concept search query are relevant to the ideas contained in the text of the query.
XML retrieval, or XML information retrieval, is the content-based retrieval of documents structured with XML. As such it is used for computing relevance of XML documents.

Reverse image search is a content-based image retrieval (CBIR) query technique that involves providing the CBIR system with a sample image that it will then base its search upon; in terms of information retrieval, the sample image is very useful. In particular, reverse image search is characterized by a lack of search terms. This effectively removes the need for a user to guess at keywords or terms that may or may not return a correct result. Reverse image search also allows users to discover content that is related to a specific sample image or the popularity of an image, and to discover manipulated versions and derivative works.

Learning to rank or machine-learned ranking (MLR) is the application of machine learning, typically supervised, semi-supervised or reinforcement learning, in the construction of ranking models for information retrieval systems. Training data consists of lists of items with some partial order specified between items in each list. This order is typically induced by giving a numerical or ordinal score or a binary judgment for each item. The goal of constructing the ranking model is to rank new, unseen lists in a similar way to rankings in the training data.
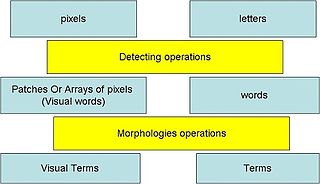
Visual words, as used in image retrieval systems, refer to small parts of an image that carry some kind of information related to the features or changes occurring in the pixels such as the filtering, low-level feature descriptors.
A 3D Content Retrieval system is a computer system for browsing, searching and retrieving three dimensional digital contents from a large database of digital images. The most original way of doing 3D content retrieval uses methods to add description text to 3D content files such as the content file name, link text, and the web page title so that related 3D content can be found through text retrieval. Because of the inefficiency of manually annotating 3D files, researchers have investigated ways to automate the annotation process and provide a unified standard to create text descriptions for 3D contents. Moreover, the increase in 3D content has demanded and inspired more advanced ways to retrieve 3D information. Thus, shape matching methods for 3D content retrieval have become popular. Shape matching retrieval is based on techniques that compare and contrast similarities between 3D models.
