Protein synthesis
Protein anabolism is the process by which proteins are formed from amino acids. It relies on five processes: amino acid synthesis, transcription, translation, post translational modifications, and protein folding. Proteins are made from amino acids. In humans, some amino acids can be synthesized using already existing intermediates. These amino acids are known as non-essential amino acids. Essential amino acids require intermediates not present in the human body. These intermediates must be ingested, mostly from eating other organisms. [6]
Amino Acid Synthesis
Polypeptide synthesis
Transcription

In transcription, RNA polymerase reads a DNA strand and produces an mRNA strand that can be further translated. In order to initiate transcription, the DNA segment that is to be transcribed must be accessible (i.e. it cannot be tightly packed). Once the DNA segment is accessible, the RNA polymerase can begin to transcribe the coding DNA strand by pairing RNA nucleotides to the template DNA strand. During the initial transcription phase, the RNA polymerase searches for a promoter region on the DNA template strand. Once the RNA polymerase binds to this region, it begins to “read” the template DNA strand in the 3’ to 5’ direction. [8] RNA polymerase attaches RNA bases complementary to the template DNA strand (Uracil will be used instead of Thymine). The new nucleotide bases are bonded to each other covalently. [9] The new bases eventually dissociate from the DNA bases but stay linked to each other, forming a new mRNA strand. This mRNA strand is synthesized in the 5’ to 3’ direction. [10] Once the RNA reaches a terminator sequence, it dissociates from the DNA template strand and terminates the mRNA sequence as well.
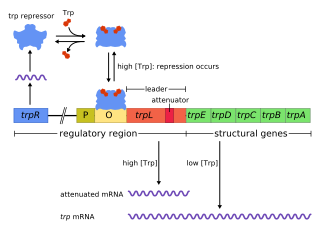
Transcription is regulated in the cell via transcription factors. Transcription factors are proteins that bind to regulatory sequences in the DNA strand such as promoter regions or operator regions. Proteins bound to these regions can either directly halt or allow RNA polymerase to read the DNA strand or can signal other proteins to halt or allow RNA polymerase reading. [11]
Translation

During translation, ribosomes convert a sequence of mRNA (messenger RNA) to an amino acid sequence. Each 3-base-pair-long segment of mRNA is a codon which corresponds to one amino acid or stop signal. [12] Amino acids can have multiple codons that correspond to them. Ribosomes do not directly attach amino acids to mRNA codons. They must utilize tRNAs (transfer RNAs) as well. Transfer RNAs can bind to amino acids and contain an anticodon which can hydrogen bind to an mRNA codon. [13] The process of bind an amino acid to a tRNA is known as tRNA charging. Here, the enzyme aminoacyl-tRNA-synthetase catalyzes two reactions. In the first one, it attaches an AMP molecule (cleaved from ATP) to the amino acid. The second reaction cleaves the aminoacyl-AMP producing the energy to join the amino acid to the tRNA molecule. [14]
Ribosomes have two subunits, one large and one small. These subunits surround the mRNA strand. The larger subunit contains three binding sites: A (aminoacyl), P (peptidyl), and E (exit). After translational initiation (which is different in prokaryotes and eukaryotes), the ribosome enters the elongation period which follows a repetitive cycle. First a tRNA with the correct amino acid enters the A site. The ribosome transfers the peptide from the tRNA in the P site to the new amino acid on the tRNA in the A site. The tRNA from the P site will be shifted into the E site where it will be ejected. This continually occurs until the ribosome reaches a stop codon or receives a signal to stop. [13] A peptide bond forms between the amino acid attached to the tRNA in the P site and the amino acid attached to a tRNA in the A site. The formation of a peptide bond requires an input of energy. The two reacting molecules are the alpha amino group of one amino acid and the alpha carboxyl group of the other amino acids. A by-product of this bond formation is the release of water (the amino group donates a proton while the carboxyl group donates a hydroxyl). [2]
Translation can be downregulated by miRNAs (microRNAs). These RNA strands can cleave mRNA strands they are complementary to and will thus stop translation. [15] Translation can also be regulated via helper proteins. For example, a protein called eukaryotic initiation factor-2 (eIF-2) can bind to the smaller subunit of the ribosome, starting translation. When elF-2 is phosphorylated, it cannot bind to the ribosome and translation is halted. [16]
Post-translational Modifications

Once the peptide chain is synthesized, it still must be modified. Post-translational modifications can occur before protein folding or after. Common biological methods of modifying peptide chains after translation include methylation, phosphorylation, and disulfide bond formation. Methylation often occurs to arginine or lysine and involves adding a methyl group to a nitrogen (replacing a hydrogen). The R groups on these amino acids can be methylated multiple times as long as the bonds to nitrogen does not exceed 4. Methylation reduces the ability of these amino acids to form hydrogen bonds so arginine and lysine that are methylated have different properties than their standard counterparts. Phosphorylation often occurs to serine, threonine, and tyrosine and involves replacing a hydrogen on the alcohol group at the terminus of the R group with a phosphate group. This adds a negative charge on the R groups and will thus change how the amino acids behave in comparison to their standard counterparts. Disulfide bond formation is the creation of disulfide bridges (covalent bonds) between two cysteine amino acids in a chain which adds stability to the folded structure. [17]
Protein folding
A polypeptide chain in the cell does not have to stay linear; it can become branched or fold in on itself. Polypeptide chains fold in a particular manner depending on the solution they are in. The fact that all amino acids contain R groups with different properties is the main reason proteins fold. In a hydrophilic environment such as cytosol, the hydrophobic amino acids will concentrate at the core of the protein, while the hydrophilic amino acids will be on the exterior. This is entropically favorable since water molecules can move much more freely around hydrophilic amino acids than hydrophobic amino acids. In a hydrophobic environment, the hydrophilic amino acids will concentrate at the core of the protein, while the hydrophobic amino acids will be on the exterior. Since the new interactions between the hydrophilic amino acids are stronger than hydrophobic-hydrophilic interactions, this is enthalpically favorable. [18] Once a polypeptide chain is fully folded, it is called a protein. Often many subunits will combine to make a fully functional protein although physiological proteins do exist that contain only one polypeptide chain. Proteins may also incorporate other molecules such as the heme group in hemoglobin, a protein responsible for carrying oxygen in the blood. [19]